Model reprezentacji aktorów społecznych van Leeuwena. Podejście korpusowe
Victoria Kamasa*

Uniwersytet im. Adama Mickiewicza w Poznaniu
Justyna Tomczak-Boczko*
Uniwersytet Szczeciński
Streszczenie: Artykuł przedstawia model reprezentacji aktorów społecznych (MRAS, ang. Social Actor Network) Theo van Leeuwena jako narzędzie do analizy sposobów konstruowania uczestników praktyk społecznych w dyskursie. Autorki rozpoczynają od syntetycznego omówienia kluczowych założeń modelu, po czym przechodzą do szczegółowej prezentacji zaproponowanych przez van Leeuwena kategorii analitycznych. Każdą z nich osadzają w praktyce badawczej, ilustrując przykładami z dotychczasowych analiz wykorzystujących MRAS. Następnie proponują ich operacjonalizację z użyciem języka zapytań korpusowych (CQL), pokazując, jak abstrakcyjne kategorie analityczne można przełożyć na konkretne procedury badawcze. Przyjęte rozwiązania umożliwiają systematyczne wyszukiwanie i eksplorację zróżnicowanych form reprezentacji aktorów społecznych w dużych zbiorach tekstów. Każda operacjonalizacja ilustrowana jest przykładami z korpusu tekstów prasowych dotyczących Osób w drodze na granicach polsko-białoruskiej i polsko-ukraińskiej w latach 2021–2022. Artykuł łączy refleksję teoretyczną z rygorem metodologicznym analizy korpusowej, oferując zarówno klarowne wprowadzenie do MRAS, jak i zestaw praktycznych narzędzi do jego zastosowania w badaniach empirycznych wspierających analizę jakościową.
Słowa kluczowe: krytyczna analiza dyskursu, reprezentacja aktorów społecznych, wspierana korpusowo analiza dyskursu
Van Leeuwen’s Social Actors Network: The Corpus Approach
Abstract: This article focuses on Theo van Leeuwen’s Social Actor Network model as a framework for analysing the representation of participants in social practices in discourse. It outlines the core assumptions of the model and systematically discusses its main analytical categories, illustrating each one with examples from previous research. The study then proposes a corpus-based operationalisation of these categories using the Corpus Query Language (CQL), which enables their identification in large-scale textual datasets. The proposed procedures are demonstrated with examples drawn from press corpora concerning the representation of People on the Move at the Polish-Belarusian and Polish-Ukrainian borders in 2021–2022. The article combines theoretical reflection with methodological innovation, showing how corpus-linguistic techniques can support the analysis of social actor representations in extensive collections of texts.
Keywords: critical discourse analysis, social actors’ representation, corpus-assisted discourse analysis
Wprowadzenie
Sposoby reprezentowania aktorów społecznych znajdują się w centrum zainteresowania wielu badań nad zagadnieniami istotnymi z punktu widzenia analiz socjologicznych: na przykład Theo van Leeuwen (2008) bada reprezentację przeciwników migracji w Australii, Zofia Trafas i Victoria Kamasa (2025) opisują, jak dyskursywnie konstruuje się OSOBY W DRODZE[1] przekraczające granice polsko-białoruską bądź polsko-ukraińską, a Emilia Zimnica-Kuzioła (2025) pochyla się nad reprezentacją osób chorych na Alzheimera w filmach im poświęconych. Ramy teoretycznej do odpowiedzi na te i podobne pytania badawcze dostarcza między innymi model reprezentacji aktorów społecznych (MRAS, ang. Social Actor Network) Theo van Leeuwena (2008). Autor oferuje w nim użyteczny zestaw narzędzi teoretycznych pozwalających wielowymiarowo opisywać dyskursywne praktyki prezentowania aktorów społecznych.
Społecznie zorientowane badania dyskursu sięgają również coraz częściej po duże zbiory tekstów, nazywane korpusami. Hubert Plisiecki i Agnieszka Kwiatkowska (2024) przyglądają się konstruowaniu pojęcia demokracji w polskich debatach parlamentarnych, Magdalena Jaszczyk-Grzyb, Anna Szczepaniak-Kozak i Sylwia Adamczak-Krysztofowicz (2023) badają mowę nienawiści w postach na Facebooku, a Sławomir Mandes i Agnieszka Karlińska (2024) analizują dokumenty Konferencji Episkopatu Polski. Badania takie pozwalają uzupełnić klasyczne badania jakościowe informacjami o wzorcach i regularnościach, pochodzącymi ze zbiorów danych na tyle dużych, że ich pełna analiza jakościowa przekracza zwykle możliwości zespołów badawczych.
Ten artykuł jest próbą połączenia tych dwóch podejść. Przedstawimy w nim główne założenia MRAS, a następnie omówimy większość z proponowanych przez Theo van Leeuwena kategorii służących do opisu sposobów reprezentowania aktorów. Opis uzupełnimy przykładami użycia tych kategorii w zorientowanych społecznie badaniach nad dyskursem. Następnie zaprezentujemy ich operacjonalizację w języku CQL umożliwiającym przeszukiwanie korpusów językowych w takich narzędziach, jak Sketch Engine (Kilgarriff i in., 2004; 2014; http://www.sketchengine.eu) czy Korpusomat (Kieraś, Kobyliński, Ogrodniczuk, 2018; Kieraś, Kobyliński, 2021; https://korpusomat.pl/). Zaproponowane operacjonalizacje zilustrujemy przykładami z badań nad reprezentacją Osób w drodze w polskiej prasie.
Notatka metodologiczna
Przedstawiając przykłady wykorzystania zaproponowanych zapytań CQL, posługujemy się korpusem OSOBY W DRODZE. Korpus ten został stworzony na potrzeby badania i porównania reprezentacji Osób w drodze przekraczających wschodnie granice Polski. Zawiera on artykuły prasowe z pierwszych czterech miesięcy kryzysu humanitarnego na granicy polsko-białoruskiej (7.08.2021–7.12.2021) oraz takiego samego okresu po pełnoskalowej inwazji Rosji na Ukrainę (24.02.2022–24.06.2022). Znajdują się w nim artykuły zarówno z gazet codziennych, jak i z tygodników. Korpus został stworzony dzięki uprzejmości firmy monitorującej media PSMM Monitoring & More, która dostarczyła zbiór artykułów związanych z badanymi zagadnieniami. Łącznie korpus zawiera blisko 9 milionów tokenów[2], stanowi więc zbiór, którego bezpośrednia analiza jakościowa jest niemożliwa.
Aby zapewnić względną uniwersalność proponowanych rozwiązań, testowałyśmy je również na innych korpusach: dotyczącym tematu ograniczenia prawa do azylu w Polsce, obejmujących debaty parlamentarne z 2025 roku, oraz dotyczącym kryzysu uchodźczego na granicach Polski w okresie od września 2021 do kwietnia 2022 roku (Tomczak-Boczko, Gołębiowska, Górny, 2023). Ze względu na niewielkie rozmiary tych korpusów mogłyśmy zweryfikować skuteczność proponowanych rozwiązań.
Narzędziem, które posłużyło nam do poszukiwania poszczególnych sposobów reprezentowania Osób w drodze w opisanym korpusie, była platforma Sketch Engine[3]. Wykorzystywałyśmy narzędzie Concordance, wyszukiwanie zaawansowane za pomocą CQL (ang. Corpus Query Language). Corpus Query Language jest językiem służącym do konstruowania złożonych zapytań, umożliwiających przeszukiwanie korpusów w celu znalezienia przykładów (zdań bądź fraz) spełniających określone warunki (Jakubíček i in., 2010) – przykładowo: wszystkich zdań zawierających równocześnie określenia „migrant” i „uchodźca”, niezależnie od ich miejsca w zdaniu i kolejności względem siebie.
Konstruując opisywane poniżej zapytania, poszukiwałyśmy kompromisu między ujęciem całościowym a ograniczeniem liczby uzyskiwanych przykładów. Zależało nam zatem, by zapytanie znajdowało możliwie jak najwięcej zdań zawierających określonego typu reprezentację aktorów społecznych. Równocześnie ważne było, by na liście z wynikami znajdowało się stosunkowo mało zdań niepasujących do poszukiwanego typu reprezentacji. Jednak ze względu na automatyczny, oparty na wzorcach językowych sposób przeszukiwania danych niemożliwe było pełne osiągnięcie wymienionych celów. Tak więc proponowane wyszukiwania nie dostarczają wszystkich przykładów określonego typu reprezentacji, a na przygotowanych za ich pomocą listach zdań znajdziemy również z pewnością przykłady niezwiązane z poszukiwaną reprezentacją.
Główne założenia MRAS
Punktem wyjścia dla rozważań prowadzonych w ramach MRAS jest rozróżnienie pomiędzy praktykami społecznymi a ich reprezentacją w dyskursie, osadzone w teorii rekontekstualizacji Basila Bernsteina. Jest to więc różnica pomiędzy robieniem (ang. doing it) a mówieniem o tym (ang. talking about it). Ta sama praktyka społeczna (ang. doing it) może być opisywana na różne sposoby, co z kolei może prowadzić do wielu różnych reprezentacji dyskursywnych. Istotne jest również założenie, „że wszystkie teksty, wszystkie przedstawienia świata i tego, co się w nim dzieje, jakkolwiek abstrakcyjne, należy interpretować jako przedstawienia praktyk społecznych” (van Leeuwen, 2008: 5). W związku z tym praktyką społeczną, która może ulec rekontekstualizacji, są zarówno działania niejęzykowe, jak na przykład ubieranie się lub zjedzenie śniadania, jak i sekwencja językowa, na przykład mowa inauguracyjna prezydenta USA (van Leeuwen, 2008: 6, 12).
Pierwszą i podstawową transformacją praktyki społecznej jest więc zastąpienie jej rzeczywistych elementów ich odpowiednikami semiotycznymi. Wówczas mają miejsce kolejne transformacje, na przykład ten sam element może pojawiać się wielokrotnie lub być uzupełniony o subiektywne reakcje uczestników, co prowadzi do różnorodnych dyskursów dotyczących tej samej praktyki. Różne rekontekstualizacje tej samej praktyki mogą też odmiennie konstruować jej cele, legitymizować ją czy oceniać.
Konsekwencją procesu rekontekstulizacji jest między innymi to, że pewne praktyki społeczne bądź ich elementy stają się mniej (lub bardziej) widoczne od innych, a „proces ten rzadko jest czytelny dla uczestników tych praktyk” (Tomczak-Boczko, 2023: 489). Dlatego Theo van Leeuwen jako zadanie badacza wyznacza poszukiwanie „podobieństwa między tym, co jest powiedziane i zapisane na temat danego aspektu rzeczywistości w różnych tekstach krążących w tym samym kontekście” w celu „złożenia układanki”, jaką są rekonstruowane dyskursy (van Leeuwen, 2009: 163). Tak wyznaczone badanie wskazuje na wykorzystanie metod korpusowych jako odpowiedniej metodologii badawczej, ponieważ to właśnie one umożliwiają analizę dużej liczby tekstów związanych z tym samym kontekstem.
Wśród elementów praktyki społecznej, które mogą podlegać rekontekstualizacji van Leeuwen wymienia między innymi uczestników, działania, czas, lokalizacje czy zasoby (van Leeuwen, 2008: 7–12). Tym pierwszym poświęca swój model rekonstrukcji aktorów społecznych, w którym dokonuje opisu i systematyzacji sposobów reprezentacji aktorów społecznych w dyskursie. Zaproponowane przez niego kategorie analityczne są przedmiotem tego opracowania.
Dyskursywne reprezentacje aktorów społecznych
Proponowany przez Theo van Leeuwena opis sposobów reprezentacji aktorów społecznych opiera się na rozgałęziających się dychotomiach (rycina 1). W centrum każdej z tych dychotomii znajduje się inny aspekt rekontekstualizacji uczestników praktyk społecznych. Kolejne rozgałęzienia pozwalają zauważyć wewnętrzne zróżnicowanie poszczególnych kategorii. Taki sposób prezentacji wiąże się jednak z tym, że kategorie te są definiowane przede wszystkim w opozycji do siebie (na przykład w parze włączenie i wyłączenie). W konsekwencji mogą one nie być jednoznaczne i nie wykluczać się wzajemnie, a bardziej złożone relacje między kategoriami nie zostały przez van Leeuwena opisane. Może to prowadzić do wątpliwości interpretacyjnych, widocznych zresztą w literaturze przedmiotu wykorzystującej MRAS. Co więcej, kategorie te nie są rozłączne, a więc ten sam fragment dyskursu może być uznany za przykład różnych opisanych poniżej typów reprezentacji.
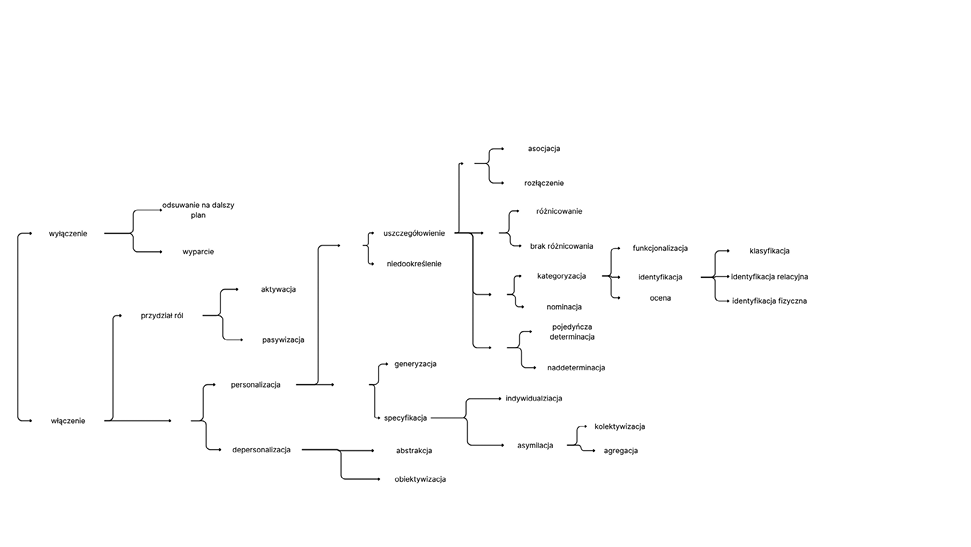
Źródło: opracowanie własne na podstawie van Leeuwen, 2008: 52.
Włączenie i wyłączenie[4]
Dychotomia ta odnosi się do sposobu uwzględniania aktorów społecznych w opisie poszczególnych wydarzeń. I tak włączenie (ang. inclusion) oznacza taki opis wydarzenia, w którym badani aktorzy społeczni są obecni. Kategoria ta jest stosunkowo rzadko przywoływana w analizach, ponieważ wydaje się, że dopiero wyłączenie wskazuje na celowość praktyk dyskursywnych. Jednak, jak wskazuje van Leeuwen, również włączanie pewnych aktorów warte jest analizy. Analizując opowiadania dla dzieci dotyczące pierwszego dnia w szkole, van Leeuwen wskazuje, że w opowiadaniach skierowanych na rynek masowy pojawiają się osoby ze szkolnego personelu pomocniczego, ale wykluczeniu podlega dyrektor, podczas gdy w opowiadaniach z innego segmentu wydawniczego („ekskluzywnego”) włączane są tylko osoby uczące i kierujące placówkami (van Leeuwen, 2008: 29).
Przyjmujemy, że wykładnikiem językowym zachodzenia włączenia jest pojawienie się nazwy badanych aktorów społecznych w okolicy czasownika wskazującego, o jakie działanie chodzi. Dla określenia „migrant” tego typu wyniki uzyskamy, stosując następujące zapytanie w języku CQL[5]:
(meet [lemma="migrant"] [tag="fin.*|bedzie.*|aglt.*|praet.*|impt.*"] -3 3)[6]
Dla badanego przez nas korpusu uzyskałyśmy następujące przykłady[7] (2836, 316,4 pmt[8]):

Źródło: korpus OSOBY W DRODZE.
Już przytoczone tu przykłady wskazują, że zaproponowane zapytanie będzie dostarczało bardzo szerokiego materiału. Jednak zgodnie z MRAS wszystkie kolejne typy reprezentacji są podtypami włączenia, co umożliwi dalsze zawężanie efektów wyszukiwania.
Po drugiej stronie tej dychotomii znajduje się wyłączenie (ang. exclusion), a więc pominięcie wybranych aktorów w opisie wydarzenia. Wśród jego wyrazistych przykładów znajdziemy: „atak spowodował paniczną ucieczkę” (Peled-Elhanan, 2010: 393), czy „zgwałcili mnie”, „krzyczą na mnie” (Tomczak-Boczko, 2023: 496). W przeprowadzonych dotychczas badaniach ten typ reprezentacji dotyczył sprawców przemocy wobec kobiet i osób nieheteronormatywnych w Meksyku (Tomczak-Boczko, 2023), wobec kobiet i mężczyzn w Subsaharyjskiej Afryce (Akinseye, 2024; 2025) czy wobec uczestników zamieszek w Izraelu (Peled-Elhanan, 2010). Wyłączenie może zatem prowadzić na przykład do usuwania z pola widzenia sprawcy wydarzeń ocenianych negatywnie.
Theo van Leeuwen proponuje tutaj dalsze rozróżnienie na supresję (ang. suppression) i odsuwanie na dalszy plan (ang. backgrounding). O pierwszej mówimy w przypadku, gdy udział badanych aktorów w praktyce społecznej zostaje całkowicie pominięty, a w tekście nie pojawia się żadne odniesienie do nich. Jak wskazuje cytowany autor, ustalenie, kogo pominięto, jest bardzo trudne i możliwe właściwie jedynie dzięki porównaniu różnych opisów tego samego wydarzenia. Tym samym analiza supresji musi pozostać domeną badań jakościowych.
W przypadku umieszczenia w tle aktorzy nie są bezpośrednio przypisywani do opisywanego działania, jednak ich obecność zostaje wspomniana w innych częściach tekstu, co umożliwia wyciągnięcie wniosków o ich zaangażowaniu. Również tutaj niełatwo określić językowe wykładniki tego sposobu reprezentacji. Przyjęłyśmy jednak, że za wskaźnik może tu służyć pojawienie się bezosobowej formy czasownika w sąsiedztwie nazwy określającej badanych aktorów społecznych:
[lemma="migrant"][]{0,30}[tag="imps.*"]
Dzięki temu uzyskałyśmy następujące przykłady (324, 35,15 pmt):

Źródło: korpus OSOBY W DRODZE.
Jak pokazują przytoczone przykłady, zaproponowane wyszukiwanie nie pozwala ustalić, w jakich przypadkach umieszcza się w tle migrantów. Umożliwia natomiast przybliżoną odpowiedź na pytanie, kogo umieszcza się w tle, kiedy mowa o migrantach.
Aktywizacja i pasywizacja
Ta dychotomia, określana przez Theo van Leeuwena jako przypisanie ról (ang. role allocation), związana jest z rolą, jaką pełnią aktorzy w praktyce społecznej. W przypadku aktywizacji badani aktorzy reprezentowani są jako siła sprawcza: „Złodzieje pobili sprzedawcę w delikatesach po tym, jak ukradli bukiety kwiatów” (Tessuto, 2017: 109–110), „bo mnie wkurzyła i ją spoliczkowałem” (Tomczak-Boczko, 2023: 492). Również w tym przypadku cytowane badania związane były z przemocą i przestępstwami, jednak ten typ reprezentacji dotyczył nie tylko sprawców, ale także ofiar (Tomczak-Boczko, 2023) czy organów ścigania (Tessuto, 2017).
Za językowy wykładnik aktywizacji uznałyśmy wystąpienie określenia badanych aktorów społecznych w roli podmiotu w zdaniu:
(meet [lemma="migrant" & tag="subst.*.nom.*"] [tag="fin.*|praet.*|impt.*"& lemma!="zostać|być"] -5 5)
z następującymi przykładami z badanego korpusu (758, 84,57 pmt):

Źródło: korpus OSOBY W DRODZE.
Z kolei z pasywizacją (ang. passivation) mamy do czynienia, jeśli uczestnicy praktyk społecznych prezentowani są jako poddawani określonym działaniom: „Przemoc domowa – 340 mężów zostało pobitych przez żony w ciągu jednego roku – rząd Lagos” (Akinseye, 2024: 246–249), „Według statystyk ISEE co piąta osoba LGBTIQ została zmuszona do wizyty u lekarza po ujawnieniu swojej tożsamości LGBT […]” (Nguyen, Clancy, 2025: 12). Konsekwencją tej reprezentacji może być na przykład konstruowanie wybranych aktorów jako biernych i pozbawionych sprawczości, na co wskazał Ingo Winkler (2011), pisząc o pracownikach korporacji.
Za językowy wykładnik pasywizacji przyjęłyśmy występowanie badanej grupy aktorów społecznych w roli podmiotów zdań w stronie biernej:
<s/> containing (meet [lemma = "migrant" & tag="subst.*.nom.*"] [tag = "ppas.**.*.*.*.m1.*.aff"] -8 8) containing [lemma="być|zostać"]
co prowadzi do uzyskania następujących przykładów (122, 16,62 pmt):

Źródło: korpus OSOBY W DRODZE.
Personalizacja i depersonalizacja
Personalizacja (ang. personalisation) to typ reprezentacji, w którym uczestnicy praktyk społecznych przedstawiani są jako ludzie. Theo van Leeuwen (2008) używa tej kategorii głównie jako tła dla przedstawienia depersonalizacji, a w dalszej części swojego tekstu szczegółowo opisuje jej podtypy, dla których proponujemy szczegółowe zapytania.
Z kolei depersonalizacja (ang. impersonalisation) jest działaniem dyskursywnym, w którym uczestników praktyk społecznych pozbawia się wymiaru ludzkiego, zamiast tego reprezentując ich za pomocą abstrakcyjnych lub konkretnych rzeczowników, które nie zawierają wśród swoich cech semantycznych cechy „ludzki”. Do przykładów należą tutaj: słowo „problemy”, używane do określenia imigrantów (van Leeuwen, 2008: 46), występujące samodzielnie przymiotniki typu „niewykwalifikowani”, „nielegalni”, „czarni” (Reisigl, 2010: 44) czy określenia miejsc: „cały ryneczek się śmieje” (Tomczak-Boczko, 2025: 243), „Jest to prawdopodobnie główna przyczyna możliwej do uniknięcia ślepoty w aborygeńskiej Australii” (Bednarek, 2020: 11).
Depersonalizacja może być realizowana przez bardzo różnorodne środki językowe, tym samym w dużym stopniu umyka możliwościom opartym na wzorcach zapytań korpusowych. Do pewnego stopnia pomocne mogą tu być jednak wskazówki leksykalne. I tak w przypadku abstrakcji, a więc zastępowania określenia uczestników praktyk społecznych pojęciami abstrakcyjnymi, możemy posłużyć się wskazówkami derywacyjnymi:
[lemma=".*migra.*" & tag="subs.*" & lemma!=".*migrant"]
Dla badanego przez nas korpusu (2 001, 223,24 pmt):

Źródło: korpus OSOBY W DRODZE.
Druga możliwość wyszukiwania oparta jest na założeniu, że depersonalizacje występować będą w podobnym kontekście co personalizacje. Jeśli ten warunek jest spełniony, możemy skorzystać z narzędzia Thesaurus w poszukiwaniu rzeczowników nieodnoszących się do ludzi, a podzielających możliwie dużą liczbę kolokacji ze słowem określającym badaną przez nas grupę społeczną. W przypadku analizowanych przez nas danych uzyskałyśmy w ten sposób określenia „migracja” i „grupa”.
Uszczegółowienie i generyzacja
Jako podtyp personalizacji uszczegółowienie (ang. specification) to taki sposób rekontekstualizacji aktorów społecznych, w którym przedstawiani są oni jako konkretne jednostki. Podobnie jak wspomniana wyżej personalizacja, uszczegółowienie dzieli się na kolejne podtypy, które szczegółowo omawiamy niżej.
Po drugiej stronie omawianej dychotomii znajduje się generyzacja (ang. genericisation) – reprezentacja uczestników praktyk społecznych jako grup, w tym szczególnie grup jednolitych: „Wszystkie kobiety, z którymi rozmawiałam […]” (Kabgani, 2013: 70). Autor sugeruje, że tego rodzaju generyzacja wiąże się z negatywną konstrukcją muzułmanek jako osób pozbawionych zdolności krytycznego myślenia.
Idąc za podanym przykładem, uznałyśmy, że w przypadku generyzacji chcemy się skupić na przykładach, w których podkreślono jedność grupy, czego wykładnikami językowymi są określenia „każdy” i „wszyscy”:
1:[lemma="wszystek|każdy"][]{0,3}2:[lemma="migrant"]&1.gender=2.gender&1.number=2.number
Uzyskałyśmy następujące przykłady (27, 3,01 pmt):

Źródło: korpus OSOBY W DRODZE.
Indywidualizacja i asymilacja
Będąca podtypem uszczegółowienia indywidualizacja (ang. individualisation) to rodzaj reprezentacji polegający na przedstawianiu uczestników praktyk społecznych jako jednostek. Przykłady z literatury przedmiotu wskazują jednak, że kategoria ta bywa rozumiana bardzo różnie i utożsamiana albo z nominacją (Roohani, 2014), albo z identyfikacją relacyjną (Salami, Ghajarieh, 2016). Sam Theo van Leeuwen wskazuje z kolei, że językowo ten typ reprezentacji demonstruje się przez użycie liczby pojedynczej rzeczowników określających badaną grupę i to właśnie taką interpretację zdecydowałyśmy się zastosować w zaproponowanym przez nas zapytaniu:
[lemma="migrant"& tag="subst:sg.*"]
Pozwala to uzyskać następujące przykłady (130, 14,5 pmt):

Źródło: korps OSOBY W DRODZE.
Asymilacja (ang. assimilation) z kolei wiąże się z reprezentacją zbiorową, a językowo łączy z użyciem liczby mnogiej tego samego rzeczownika: „Pielęgniarki odegrały ważną rolę w walce z nową falą epidemii koronawirusa” (Gong i in., 2023: 12) czy „Żonaci mężczyźni cierpią wykorzystywani seksualnie w milczeniu” (Akinseye, 2024: 252). Cytowani autorzy wskazują, że ten typ reprezentacji może przyczyniać się do budowania dyskursywnego poczucia wspólnego doświadczenia czy wspólnego wysiłku osób, których dotyczy.
Przykłady asymilacji odnajdziemy, posługując się zapytaniem:
[lemma="migrant"& tag="subst.pl.*"]
które prowadzi do uzyskania następujących przykładów (5 055,563,97 pmt):

Źródło: korpus OSOBY W DRODZE.
Autor MRAS proponuje tu dalsze rozróżnienie na dwa typy asymilacji. Pierwszym z nich jest agregacja (ang. aggregation), czyli taka reprezentacja, w której uczestnicy są w jakiś sposób liczeni bądź prezentowani z perspektywy statystyk. Przyjęłyśmy, że na poziomie językowym będzie się to demonstrować przez obecność liczebników poprzedzających określenie badanej grupy:
[tag="num.*.*.m1|n.*"][]{0,3}[lemma="migrant"]
Pozwala to uzyskać następujące przykłady (536, 59,9 pmt):

Źródło: korpus OSOBY W DRODZE.
Drugim typem asymilacji jest kolektywizacja (ang. collectivisation), która obejmie wszystkie pozostałe przykłady reprezentacji tego typu.
Nieokreślenie i określenie
Kolejne dwa typy personalizacji związane są ze stopniem i sposobem, w jaki tożsamość uczestników praktyk społecznych jest sprecyzowana. Określenie (ang. determination) wiąże się z wyraźną identyfikacją aktora lub grupy aktorów. Podobnie jak w przypadku uszczegółowienia dzieli się ono na kolejne podtypy, które umożliwiają wyszukiwanie jego przykładów. Określenie może mieć konkretne cele: analizując japońskie informacje prasowe na temat ruchu MeToo, Jiayu Zhang, Chengzhi Sun i Ying Hu (2022) zauważają, że ofiary molestowania seksualnego są inaczej przedstawiane w zależności od ich pochodzenia. W przypadku cudzoziemek podawano ich nazwiska i imiona: „Baiq Nuril Maknun, jako twarz indonezyjskiego ruchu #MeToo, była reprezentowana przez swoje prawdziwe imię i nazwisko, będąc przedstawiana jako odważna kobieta, która odważyła się powiedzieć ‘nie’” (Zhang, Sun, Hu, 2022: 4).
Nieokreślenie (ang. indetermination) jest z kolei typem reprezentacji, w którym tożsamość uczestników praktyk społecznych pozostaje nieznana, co Theo van Leeuwen wiąże z tym, że „nie jest uznawana za istotną dla odbiorcy” (van Leeuwen, 2008: 40). Aktorzy przedstawiani są jako anonimowe jednostki bądź grupy takich jednostek. Cytowani wyżej autorzy stwierdzają, że „zdecydowana większość japońskich ofiar jest przedstawiana jako nieokreślone, anonimowe osoby lub grupy, takie jak 16-letnia dziewczyna i około 60 kobiet” (Zhang, Sun, Hu, 2022: 4). Skrajnym przykładem nieokreślenia jest sposób wizualnej prezentacji byłych członków włoskiej Camorry: są oni przedstawiani od tyłu, bez żadnych szczegółów umożliwiających ich identyfikację (Caliendo, 2017).
Na poziomie językowym nieokreślenie może wyrażać się co najmniej na dwa sposoby:
- Poprzez wyrażanie nieokreślenia przeznaczonymi do tego środkami leksykalnymi, takimi jak „jakiś” czy „którykolwiek”. Tego typu przykłady uzyskamy, używając następującego zapytania:
[lemma="jakiś|któryś|którykolwiek|jakikolwiek"][]{0,2}[lemma="migrant"]
Na przykład (11, 1.23 pmt):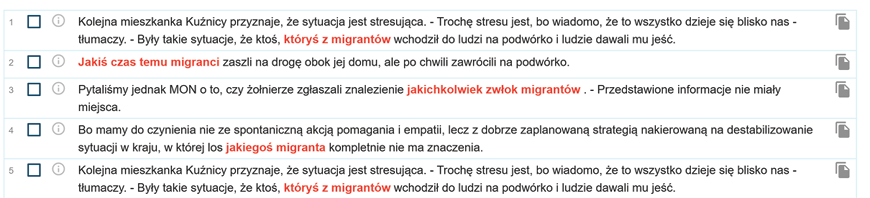
Rycina 11. Przykłady nieokreślenia
Źródło: korpus OSOBY W DRODZE. - Poprzez zastąpienie nazwy grupy określeniem „ktoś” lub podobnymi. Aby uniknąć bardzo dużej liczby mało istotnych przypadków, zdecydowałyśmy się tutaj na zawężenie kontekstu w taki sposób, by w pobliżu słowa „ktoś” znajdowało się określenie badanej grupy. W tym przypadku wyszukiwanie odbywa się w dwóch krokach. Po pierwsze, używamy po kolei następujących zapytań:
[lemma="ktoś"]-
( [lemma="wszyscy" & tag="subst.*"] | [lemma="niektóry|wiele|niewiele|żaden"& gender="m1" & tag="adj.*"] ) [tag!="subst.*" & tag!="adj.*" & lemma!="z"& tag!="ger.*"]{0,2} within <s/>
Następnie dla tak wybranych konkordancji wybieramy opcję filtruj i w zaawansowanych ustawieniach wybieramy CQL: [lemma="migrant"], a odległość ustawiamy na 20 tokenów w każdą stronę.
Pozwoliło to uzyskać następujące przykłady (95, 10,6 pmt):

Rycina 12. Przykłady nieokreślenia
Źródło: korpus OSOBY W DRODZE
Połączenie i rozdzielenie
Połączenie i rozdzielenie są podtypami określenia i odnoszą się do prezentowania aktorów społecznych jako grup. W przeciwieństwie do opisanych wyżej typów reprezentacji tutaj mamy do czynienia z grupami, którym nie jest nadawana jedna wspólna nazwa.
W przypadku połączenia (ang. association) aktorzy są więc wymieniani jako element większej grupy, którą coś łączy: „Dzisiaj niech Bóg nam będzie miłosierny – ataki na małżeństwo i rodzinę stają się z każdym dniem coraz silniejsze i coraz bardziej radykalne […]” (Kamasa, 2013: 146). W analizie tego typu reprezentacji istotne jest nie tylko to, z jakimi innymi grupami dochodzi do połączenia, ale także to, co jest jego podstawą.
Przyjęłyśmy, że w polszczyźnie tego typu połączenia charakteryzuje pojawienie się nazwy badanej grupy, spójnika „i” oraz kolejnego rzeczownika określającego inną grupę społeczną[9], co uzyskamy, stosując zapytania:
[tag = "subst.*"] [tag!="prep.*|qub.*"]{0,3}[lemma = "i"] [lemma = "migrant"]within <s/>[lemma = "migrant"] [tag!="prep.*|qub.*"]{0,3}[lemma = "i"] [tag = "subst.*"]within <s/>
Dzięki temu wyszukiwaniu uzyskałyśmy następujące przykłady (48, 8.9 pmt):

Źródło: korpus OSOBY W DRODZE.
Rozdzielenie (ang. dissociation) jest z kolei takim sposobem reprezentacji, w którym grupa zostaje rozwiązana bądź podzielona na mniejsze części. Podawane przez autora teorii przykłady tej relacji odnoszą się do prostego rozłączenia wcześniej połączonej grupy. Jednak John Trent (2012) mówi o rozłączeniu w kontekście dystansowania się jednego aktora społecznego od innych. Takie podejście uznajemy za szczególnie istotne, a jego wyrazistym przykładem jest pochodzące z badanego korpusu stwierdzenie: „Nie mamy do czynienia z ekonomicznymi migrantami, tylko z autentycznymi uchodźcami”. Tego typu przypadki znajdziemy pośród wyników zapytania (69, 7,7 pmt):
((meet(meet 1:[lemma = "migrant"] 2:[tag="subst.*"] -8 8) [lemma="nie"]-5 5)& 1.case=2. case &1.number=2.number within <s/>)
Pozwoliło to odnaleźć między innymi następujące przykłady:
- „Nie przyjęła się też narzucana przez Łukaszenkę narracja, że to są uchodźcy z Afganistanu, a nie głównie nielegalni migranci o podłożu ekonomicznym”;
- „I wydzwanianie do nauczycieli – dlaczego robią to dla żołnierzy, a nie dla migrantów”;
- „Nawet niektórzy księża deklarują, że oni będą się modlić nie za migrantów, ale wyłącznie za polskie wojsko i o ochronę granic”.
Jego efektem jest natomiast również bardzo wiele zdań niezwiązanych z analizowanym typem reprezentacji[10], a więc zawęża ono nasze pole poszukiwań, ale nadal wymaga szczegółowej analizy jakościowej.
Nominacja i kategoryzacja
Kolejnym podtypem określenia jest nominacja (ang. nomination), czyli taki typ reprezentacji, w którym uczestnicy praktyk społecznych określani są za pomocą indywidualnych i jednoznacznie powiązanych z nimi etykiet językowych: „Shagufta, 25-letnia redaktorka muzułmańskiego magazynu Q News […]” (Kabgani, 2013: 75). Ten typ reprezentacji wskazuje między innymi, jacy aktorzy społeczni są dostatecznie ważni, by podawać ich dokładne dane. Zwracają na to uwagę między innymi Rahman Sahragard i G. Davatgarzadeh (2010), uznając częstą nominację (sławnych) kobiet w podręcznikach za wskaźnik inkluzywności tych tekstów.
Na poziomie językowym nominacja będzie reprezentowana przez użycie nazw własnych, takich jak imię i nazwisko, dla określenia poszczególnych uczestników praktyk społecznych. Niestety, Sketch Engine nie umożliwia przeszukiwania korpusów pod tym kątem. Pomocne natomiast może być tu narzędzie Anonymizer (Oleksy, Ropiak, Walkowiak, 2021), którego pierwotnym przeznaczeniem jest anonimizacja zebranych danych. Po przeprowadzeniu anonimizacji na analizowanych przez nas danych uzyskamy nową wersję korpusu, w której wszystkie nazwy własne osób zostaną zastąpione frazą [OSOBA]. W następnej kolejności już w Sketch Engine możemy wyszukać wszystkie zdania z tą frazą:
[word="."][word="OSOBA"][word="."]
Dla przykładowej próbki danych uzyskałyśmy następujące przykłady[11]:

Źródło: korpus OSOBY W DRODZE.
Pozyskane przykłady demonstrują, że uzyskamy dzięki temu listę wszystkich zdań, w których wystąpiły nazwy własne osób. Wyłonienie tych, które odnoszą się do badanej przez nas grupy aktorów społecznych, pozostanie domeną analizy jakościowej.
Kategoryzacja (ang. categorisation) to z kolei taki typ dyskursywnej konstrukcji uczestników praktyk społecznych, w którym przedstawia się ich poprzez cechy lub funkcje wspólne dla nich i dla innych aktorów społecznych. Theo van Leeuwen zauważa, że taki typ reprezentacji tworzy ogólny obraz grupy i może prowadzić do niwelowania indywidualnych różnic między jej członkami. Autor modelu reprezentacji aktorów społecznych proponuje dalszy podział kategoryzacji na podtypy: funkcjonalizację, identyfikację i ocenę.
Funkcjonalizacja, identyfikacja i ocena
Funkcjonalizacja (ang. functionalisation) wiąże z prezentowaniem aktorów społecznych z perspektywy ich działań, jak na przykład wykonywanego zawodu czy pełnionej roli społecznej: „Van Kerkhove, epidemiolog ze Stanów Zjednoczonych, pochwaliła chińską infrastrukturę zdrowia publicznego […]” (Gong i in., 2023: 13). Istotne jest tu więc pytanie, kogo i ze względu na jakie działanie funkcjonalizuje się w badanym dyskursie.
Założyłyśmy, że na poziomie językowym funkcjonalizacja będzie wiązać się z pojawieniem się wyrazów wskazujących wykonywany zawód bądź pełnioną rolę społeczną. Niestety, Sketch Engine nie umożliwia zgeneralizowanego wyszukiwania takich określeń, konieczne jest zatem posłużenie się jakąś ich listą. Z pomocą może przyjść tutaj lista kluczowych rzeczowników, na której wyszukamy takie nazwy pojawiające się w badanym materiale, bądź Słowosieć (Dziob, Piasecki, Rudnicka, 2019), w której pod hiperonimem „człowiek ze względu na swoje zajęcie” znajdziemy długą listę słów, których użycie będzie się wiązać z funkcjonalizacją. Dodatkowo przyjęłyśmy także, że typowo nazwa taka będzie występować bezpośrednio po imieniu bądź nazwisku[12]:
1:[tag="subst.sg.*"][]{0,1}[lemma=","] 2:[lemma="nauczyciel|lekarz|murarz|fryzjer"]& 1.case=2.case
W przypadku analizowanego przez nas materiału pozwoliło to uzyskać następujące wyniki (101, 11,27 pmt):

Źródło: korpus OSOBY W DRODZE.
Jak widać, przytoczone przykłady nie odnoszą się bezpośrednio do badanej przez nas grupy aktorów społecznych. Pozwalają natomiast częściowo odpowiedzieć na pytanie, kto jest funkcjonalizowany w badanym dyskursie.
Identyfikacja (ang. identification) jest z kolei rodzajem reprezentacji, w którym na pierwszy plan wysuwają się różne typy tożsamości uczestników praktyk społecznych. Theo van Leeuwen wyróżnia trzy podtypy identyfikacji:
- ze względu na podstawowe kategorie używane w danym społeczeństwie (klasyfikacja – ang. classification): użycie tytułów Mr., Mrs. czy Miss, które nie tylko identyfikują aktorów społecznych ze względu na płeć, ale również wskazują stan cywilny kobiet (Salami, Ghajarieh, 2016);
- ze względu na cechy fizyczne (identyfikacja fizyczna – ang. physical identification): „brodacze” (Krendel, McGlashan, Koller, 2022: 9);
- ze względu na relacje (identyfikacja relacyjna – ang. relational identification): „To jest jego matka. Nazywa się Zahra” (Salami, Ghajarieh 2016: 75).
Przyjęłyśmy, że na poziomie językowym dwa pierwsze podtypy identyfikacji odnajdziemy, przyglądając się przymiotnikom, za pomocą których opisywana jest badana przez nas grupa społeczna:
(1:[tag="adj.*." & lemma!="który|inny|każdy|ci|ten|wszyscy|niektóry|kolejny|jedyny|żaden|taki"][]{0,2} 2:[lemma="migrant" & tag="subst.*."] & 1.case=2.case & 1.number=2.number within <s/>)
Uzyskałyśmy następujące przykłady (573, 63,93 pmt):

Źródło: korpus OSOBY W DRODZE.
Dalsza analiza, prowadząca do podziału na poszczególne kategorie, a także do eliminacji nierelewantnych przykładów, pozostaje domeną analizy jakościowej.
Dodatkowo wyszukiwanie identyfikacji fizycznej możemy wzbogacić o frazę:
[lemma="człowiek"][lemma="z|o"][]{0,1}1:[tag="adj.*"] 2:[lemma="oko|włos|głowa|ręka|noga|twarz"& tag="subst.*"]& 1.case=2.case
Z kolei przypadki klasyfikacji ze względu na wiek pomoże odnaleźć:
[lemma="kobieta"][]{0,2}[tag="num.*"][lemma="rok" & tag="subst.pl.gen.*"]|1:[lemma="..-letni" & tag="adj.*"][]{0,1}2:[lemma="kobieta" & tag="subst.*"] & 1.case=2.case
a tej ze względu na pochodzenie:
[lemma="migrant"][lemma="z"][tag="subst.*.gen.*"][lemma="migrant"][tag="pact.*"][lemma="z"][tag="subst.*.gen.*"]
W przypadku identyfikacji relacyjnej przyjęłyśmy, że jej wskaźnikiem językowym będzie pojawienie się przed nazwą badanej grupy zaimka dzierżawczego bądź rzeczownika w celowniku po tej nazwie:
[tag="ppron3.*.*.*"][]{0,1}[lemma="matka"][lemma="matka"][tag="subst.*.gen.*"]
Tak sformułowane zapytanie pozwoliło uzyskać następujące przykłady[13] (129, 14,39 pmt):

Źródło: korpus OSOBY W DRODZE.
Ostatnim podtypem klasyfikacji jest ocena (ang. appraisement), czyli używanie wobec uczestników praktyk społecznych etykiet, które odnoszą się do dobra, zła, tego, czy są oni przedmiotem miłości, czy nienawiści. Wśród przykładów oceny pojawiającej się manosferze Alexandra Krendel, Mark McGlashan i Veronika Koller (2022: 9) wymieniają: „bitch, bitches, slut, whore, whores, cuck, niceguy”[14]. Natomiast Amy Booth zauważa, iż w dyskursie białych ekstremistów reprezentacja innych grup łączy się z jednoznacznymi ocenami, na przykład: „Tylko żałośnie głupie libertyny, komuchy i chuje tego nie rozumieją” (Booth, 2023: 4).
Na poziomie językowym wskaźnikiem oceny będą nacechowane określenia używane w stosunku do badanej grupy. W Słowosieci (Dziob, Piasecki, Rudnicka, 2019) znajdziemy hiperonimy „człowiek, którego ocenia się negatywnie” oraz „człowiek, którego ocenia się pozytywnie”, dzięki którym możemy uzyskać listę wszystkich tego typu wyrazów w polszczyźnie, a następnie użyć jej w wyszukiwaniu przykładów z wszystkimi terminami z listy. Rozwiązanie to jednak doprowadzi do uzyskania długiej listy przykładów, z których jedynie część będzie odnosić się do badanej przez nas grupy. Drugą możliwością jest wykorzystanie Thesaurusa i przeszukanie uzyskanej listy odpowiedników pod kątem nacechowanych określeń. I tak na przykład na takiej liście dla słowa „pedał” w korpusie referencyjnym plTenTen19 znajdziemy słowa „idiota” i „debil”. Na takiej liście znajdziemy jednak jedynie słowa o stosunkowo wysokich częstotliwościach, co jest znaczącym ograniczeniem tej metody. Poszukiwanie ocen w dużej mierze pozostanie zatem domeną analizy jakościowej.
Nadmierna reprezentacja
Z nadmierną reprezentacją (ang. overdetermination) mamy do czynienia w sytuacji, gdy aktorzy społeczni przedstawiani są jako uczestnicy więcej niż jednej praktyki społecznej naraz. Przykłady, które podaje w swojej książce Theo van Leeuwen, odnoszą się w większości do złożonych relacji pomiędzy poszczególnymi reprezentacjami w tekście, które przekraczają granicę zdania, a nawet akapitu. Odnajdywanie tego typu relacji musi pozostać domeną pogłębionej analizy jakościowej.
Na bardzo podstawowym i związanym z dużym uproszczeniem poziomie możemy przyjąć, że językowym wskaźnikiem nadmiernej reprezentacji będzie pojawienie się określenia analizowanej grupy społecznej jako podmiotu w zdaniach o co najmniej dwóch czasownikach. Tego typu przykłady odnajdziemy za pomocą następującego wyszukiwania (136, 15,16 pmt):
(1:[lemma="migrant" & tag="subst.*.nom.*"] []{0,10}2:[tag= "fin.*.ter.*|praet.*ter.*|impt.*ter.*"][]{1,10}3:[tag= "fin.*.ter.*|praet.*ter.*|impt.*ter.*"] within <s/>) &1.number=2.number&2.number=3.number

Źródło: korpus OSOBY W DRODZE.
Natomiast również w przypadku tak uzyskanych wyników po stronie ich jakościowej analizy pozostanie określenie, czy mamy do czynienia z czasownikami wskazującymi jedną praktykę społeczną, czy więcej.
Podsumowanie
Opisany w tekście model reprezentacji aktorów społecznych dostarcza spójnych, wielowymiarowych i dobrze osadzonych w literaturze narzędzi teoretycznych do analizy reprezentacji aktorów społecznych w dyskursie. Liczne zaproponowane przez Theo van Leeuwena kategorie pozwalają spojrzeć na te reprezentacje na różne sposoby. Powszechność użycia MRAS w literaturze przedmiotu umożliwia z kolei porównania zarówno między językami, jak i między różnymi typami źródeł. Uznajemy to za istotne przesłanki przemawiające za przydatnością tego modelu.
Z kolei zaproponowane tutaj operacjonalizacje pochodzących z MRAS kategorii otwierają możliwość zastosowania go do analiz dużych zbiorów tekstów, takich jak choćby Polski Korpus Parlamentarny (Ogrodniczuk, 2018) czy duże zbiory tekstów prasowych. Zastosowanie dobrze zdefiniowanych kategorii analitycznych do dużych zbiorów tekstów pozwoli na odnajdywanie wzorców i regularności, w tym na przykład najbardziej typowych sposobów kategoryzacji czy identyfikacji wybranych aktorów społecznych. Ta typowość i powtarzalność mogą zostać uznane za istotne czynniki w dalszej refleksji nad społecznym znaczeniem tych reprezentacji.
Oparcie opisanych operacjonalizacji na wzorcach leksykalno-gramatycznych charakterystycznych dla polszczyzny zapewnia ich względną uniwersalność, zarówno w odniesieniu do badanej grupy, jak i typu badanych tekstów. Z perspektywy zastosowania przedstawionych zapytań nie będzie więc ważne, czy przyglądamy się reprezentacji ojca w polskim dyskursie parlamentarnym, czy wolontariuszy z konkretnego festiwalu na zamkniętej i przeznaczonej dla nich grupie dyskusyjnej. W obu przypadkach uzyskamy podobne i porównywalne między sobą wyniki.
Ograniczenia interpretacyjne
Przy interpretacji uzyskanych za pomocą zaproponowanych metod wyników konieczna jest jednak pewna ostrożność. Pozwalają one bowiem uzyskać odpowiedź na pytanie o to, jakie mamy przykłady określonego typu reprezentacji, jeśli operacjonalizujemy ją w przyjęty sposób. Operacjonalizacje te zawierają słowo/słowa określające aktora społecznego oraz zapis językowego sposobu wyrażania badanej reprezentacji.
Po pierwsze więc, wyniki ograniczone są do tych reprezentacji, w których użyto wybranych przez nas słów. I tak na przykład, jeśli centrum naszych zapytań będzie słowo „migrant”, a przedmiotem badania reprezentacja Osób w drodze, pominiemy w analizie wszystkie inne reprezentacje tych Osób, a więc te za pomocą takich słów, jak „uchodźca”, „imigrant” czy „cudzoziemiec”, ale także te, w których odnoszono się do Osób za pomocą zaimków czy w ogóle bezosobowo.
Po drugie, pominiemy w analizie także te wszystkie przykłady, które wymykają się przyjętemu sposobowi operacjonalizacji językowej. Zwraca na to uwagę sam van Leeuwen, wskazując na brak wzajemnej jednoznaczności, a więc symetrycznego dopasowania kategorii socjologicznych i językowych. Będzie to dotyczyło szczególnie bardziej złożonych i subtelnych sposobów reprezentowania aktorów społecznych, które odnajdujemy dzięki pogłębionej analizie jakościowej. I tak poszukując przykładów rozdzielenia zaproponowanymi metodami, nie znajdziemy zdania: „Brać matki z dziećmi, a wydalać ojców czy starszych braci”, które zawiera wyraźne rozdzielenie i wydaje się istotne z punktu widzenia analizowanego dyskursu.
Zachowanie ostrożności w interpretacjach uzyskanych wyników jest szczególnie istotne w odniesieniu do relacji ilościowych między badanymi typami reprezentacji. Proponowane narzędzia nie pozwalają jednoznacznie odpowiedzieć na pytanie, czy w badanym zbiorze więcej jest pasywizacji, czy aktywizacji albo czy przeważa asymilacja, czy indywidualizacja.
Pozwalają one natomiast wskazać pewne tendencje, szczególnie jeśli obserwowane różnice są duże. Przede wszystkim umożliwiają one jednak obserwację wzorców i regularności w dużym zbiorze tekstów. Dzięki jakościowej analizie uzyskanych przykładów możemy więc wskazać, jakich grup dotyczy pojawiająca się w tekstach asymilacja, czy też w przypadku jakich działań mamy do czynienia z aktywizacją, a w przypadku jakich z pasywizacją. Dotychczasowe interpretacje opierające się na MRAS bazowały przede wszystkim na analizach jakościowych w niewielkich zbiorach tekstów. Proponowane w niniejszym artykule metody pozwolą badać również duże korpusy językowe, w tym także referencyjne, liczące na przykład 1,5 miliarda słów (Narodowy Korpus Języka Polskiego).
Proponowane metody z pewnością nie zastąpią analizy jakościowej. Mogą ją jednak wspierać i uzupełniać – po pierwsze, dostarczając fragmentów tekstów, które mogą być dalej analizowane jakościowo, po drugie, umożliwiając stawianie hipotez dotyczących powtarzających się reprezentacji, które mogą być następnie rozwijane i pogłębiane w analizie jakościowej mniejszych zbiorów tekstów o dużej wadze dla badanego tematu, po trzecie, sugerując tendencje ilościowe w odniesieniu do poczynionych na podstawie analizy jakościowej przypuszczeń. Mamy nadzieję, że zaproponowane przez nas narzędzia przyczynią się do łączenia podejścia ilościowego i jakościowego w wykorzystaniu opisanego przez Theo van Leeuwena modelu reprezentacji aktorów społecznych.
Autorzy
* Victoria Kamasa
* Justyna Tomczak-Boczko
Cytowanie
Victoria Kamasa, Justyna Tomczak-Boczko (2026), Model reprezentacji aktorów społecznych van Leeuwena. Podejście korpusowe, „Przegląd Socjologii Jakościowej”, t. XXII, nr 2, s. 6–31, https://doi.org/10.18778/1733-8069.22.2.01
Bibliografia
Akinseye Tolulope (2024), Social Actors’ Representations in Newspaper Headlines on Domestic Violence against Men and Women in Sub-Saharan, Africa, „Athens Journal of Mass Media and Communications”, vol. 10(4), s. 233–258, https://www.athensjournals.gr/media/2024-10-4-3-Akinseye.pdf (dostęp: 7.10.2025).
Akinseye Tolulope (2025), A Corpus-Assisted Critical Discourse Analysis of Social Actors and Actions in Newspaper Reportage on Domestic Violence in Nigeria, „Corpus-based Studies across Humanities”, vol. 3(2), s. 369–392, https://doi.org/10.1515/csh-2025-0013
Bednarek Monika (2020), Invisible or high-risk: Computer-assisted discourse analysis of references to Aboriginal and Torres Strait Islander people(s) and issues in a newspaper corpus about diabetes, „PLoS ONE”, vol. 15(6), e0234486, https://doi.org/10.1371/journal.pone.0234486
Booth Amy (2023), Fractured in-group identity (re)negotiation in an online white nationalist forum, „Applied Corpus Linguistics”, vol. 3(3), 100062, https://doi.org/10.1016/j.acorp.2023.100062
Caliendo Giuditta (2017), Representing the Camorra as a Global Criminal Entity: A Multimodal Discourse Analysis, „I-LanD Journal: Identity, Language and Diversity”, no. 1, s. 15–37, https://www.academia.edu/34618291/Balirano_G_Caliendo_G_Sambre_P_eds_2017_The_Discursive_Representation_of_Globalised_Organised_Crime_Crossing_Borders_of_Languages_and_Cultures (dostęp: 7.10.2025).
Dziob Agnieszka, Piasecki Maciej, Rudnicka Ewa (2019), plWordNet 4.1 – a Linguistically Motivated, Corpus-based Bilingual Resource, [w:] Piek Vossen, Christiane Fellbaum (red.), Proceedings of the 10th Global Wordnet Conference, Wrocław: Global Wordnet Association, s. 353–362, https://doi.org/10.18653/v1/2019.gwc-1.45
Gong Jiankun, Firdaus Amira, Aksar Iffat Ali, Alivi Mumtaz Aini, Xu Jinghong (2023), Intertextuality and ideology: Social actor’s representation in handling of COVID-19 from China daily, „Journalism”, vol. 24, s. 2741–2761, https://doi.org/10.1177/14648849231157243
Jakubíček Miloš, Kilgarriff Adam, McCarthy Diana, Rychlý Pavel (2010), Fast syntactic searching in very large corpora for many languages, [w:] Ryo Otoguro, Kiyoshi Ishikawa, Hiroshi Umemoto, Kei Yoshimoto, Yasunari Harada (red.), Proceedings of the 24th Pacific Asia Conference on Language, Information and Computation, Tokyo: Institute of Digital Enhancement of Cognitive Processing, Waseda University, s. 741–747, https://aclanthology.org/Y10-1086.pdf (dostęp: 7.10.2025).
Jaszczyk-Grzyb Magdalena, Szczepaniak-Kozak Anna, Adamczak-Krysztofowicz Sylwia (2023), A corpus-assisted critical discourse analysis of hate speech in German and Polish social media posts, „Moderna Språk”, vol. 117(1), s. 44–71, https://doi.org/10.58221/mosp.v117i1.11518
Kabgani Sajad (2013), The Representation of Muslim Women in Non-Islamic Media: A Critical Discourse Analysis Study on Guardian, „International Journal of Women’s Research”, vol. 2(1), s. 57–78, https://www.researchgate.net/publication/239522538_The_Representation_of_Muslim_Women_in_Non-Islamic_Media_A_Critical_Discourse_Analysis_Study_on_Guardian (dostęp: 7.10.2025).
Kamasa Victoria (2013), Rodzina w dyskursie polskiego Kościoła katolickiego. Badania korpusowe z perspektywy Krytycznej Analizy Dyskursu, „Socjolingwistyka”, vol. 27, s. 139–152, http://hdl.handle.net/10593/10319 (dostęp: 7.10.2025).
Kieraś Witold, Kobyliński Łukasz (2021), Korpusomat – stan obecny i przyszłość projektu, „Język Polski”, R. CI, z. 2, s. 49–58, https://doi.org/10.31286/JP.101.2.4
Kieraś Witold, Kobyliński Łukasz, Ogrodniczuk Maciej (2018), Korpusomat – a Tool for Creating Searchable Morphosyntactically Tagged Corpora, „Computational Methods in Science and Technology”, vol. 24(1), s. 21–27, https://doi.org/10.12921/cmst.2018.0000005
Kilgarriff Adam, Baisa Vít, Bušta Jan, Jakubíček Miloš, Kovář Vojtěch, Michelfeit Jan, Rychlý Pavel, Suchomel Vít (2014), The Sketch Engine: ten years on, „Lexicography”, vol. 1, s. 7–36, https://link.springer.com/article/10.1007/s40607-014-0009-9 (dostęp: 7.10.2025).
Kilgarriff Adam, Rychlý Pavel, Smrž Pavel, Tugwell David (2004), The Sketch Engine, [w:] Geoffrey Williams, Sandra Vessier (red.), Proceedings of the 11th EURALEX International Congress, Lorient: Université de Bretagne-Sud, s. 105–116, http://www.sketchengine.co.uk/wp-content/uploads/The_Sketch_Engine_2004.pdf (dostęp: 7.10.2025).
Krendel Alexandra, McGlashan Mark, Koller Veronika (2022), The representation of gendered social actors across five manosphere communities on Reddit, „Corpora”, vol. 17(2), s. 291–321, https://doi.org/10.3366/cor.2022.0257
Leeuwen Theo van (2008), Discourse and Practice. New Tools for Critical Discourse Analysis, Oxford: Oxford University Press.
Leeuwen Theo van (2009), Discourse as the Recontextualization of Social Practice: A Guide, [w:] Ruth Wodak, Michael Meyer (red.), Methods of critical discourse analysis, London–Thousand Oaks: Sage, s. 161–179.
Mandes Sławomir, Karlińska Agnieszka (2024), W stronę nowej metodologii analizy treści. Podobieństwa i różnice pomiędzy modelowaniem tematycznym i jakościową analizą treści, „Przegląd Socjologii Jakościowej”, t. XX, nr 4, s. 118–143, https://doi.org/10.18778/1733-8069.20.4.06
Nguyen Minh Hieu, Clancy Brian (2025), Representations of LGBT people in Vietnamese online newspapers: A corpus-assisted critical discourse study, „Discourse & Society”, vol. 37(2), s. 1–12, https://doi.org/10.1177/09579265251354856
Ogrodniczuk Maciej (2018), Polish Parliamentary Corpus, CLARIN-PL digital repository, http://hdl.handle.net/11321/467 (dostęp: 7.10.2025).
Oleksy Marcin, Ropiak Norbert, Walkowiak Tomasz (2021), Automated anonymization of text documents in Polish, „Procedia Computer Science”, vol. 192, s. 1323–1333, https://doi.org/10.1016/j.procs.2021.08.136
Peled-Elhanan Nurit (2010), Legitimation of massacres in Israeli school history books, „Discourse & Society”, vol. 21(4), s. 377–404, https://doi.org/10.1177/0957926510366195
Plisiecki Hubert, Kwiatkowska Agnieszka (2024), Discovering Representations of Democracy in Big Data: Purposive Semantic Sample Selection for Qualitative and Mixed-Methods Research, „Przegląd Socjologii Jakościowej”, t. XX, nr 4, s. 18–43, https://doi.org/10.18778/1733-8069.20.4.02
Przepiórkowski Adam, Bańko Mirosław, Górski Rafał L., Lewandowska-Tomaszczyk Barbara, Łaziński Marek (2012), Narodowy korpus języka polskiego, „Biuletyn Polskiego Towarzystwa Językoznawczego”, nr 47, s. 47–55, http://pracownicy.uwm.edu.pl/aleksander.kiklewicz/warianty_jezyka.pdf#page=47 (dostęp: 7.10.2025).
Reisigl Martin (2010), Dyskryminacja w dyskursach, „Tekst i dyskurs. Text und diskurs”, nr 3, s. 27–61, https://bazhum.muzhp.pl/media/texts/tekst-i-dyskurs-text-und-diskurs/2010-tom-3/tekst_i_dyskurs_text_und_diskurs-r2010-t3-s27-61.pdf (dostęp: 7.10.2025).
Roohani Ali (2014), Male and Female Social Actor Representation in Four Corners 4: A Critical Discourse Perspective, „Iranian Journal of Research in English Language Teaching”, vol. 2(2), s. 24–35.
Sahragard Rahman, Davatgarzadeh G. (2010), The Representation of Social Actors In Interchange Third Edition Series: A Critical Discourse Analysis, „The Journal of Teaching Language Skills (JTLS)”, vol. 2(1), s. 67–89.
Salami Ali, Ghajarieh Amir (2016), Culture and Gender Representation in Iranian School Textbooks, „Sexuality & Culture”, vol. 20, s. 69–84, https://doi.org/10.1007/s12119-015-9310-5
Tessuto Girolamo (2017), Woman Robbed and Punched on London Street: Linguistic and Discursive Representation of Offender and Victim Social Actors in Crime News Headlines, „I-LanD Journal: Identity, Language and Diversity”, vol. 1, s. 103–125.
Tomczak-Boczko Justyna (2023), If not a ‘macho’, then who did it? Social actors and the violence of Mexico, „Discourse & Society”, vol. 34(4), s. 485–501, https://doi.org/10.1177/09579265221137194
Tomczak-Boczko Justyna (2025), Maska macho. Językoznawcze poszukiwania współczesnych modeli męskości w Meksyku, Szczecin: Wydawnictwo Naukowe Uniwersytetu Szczecińskiego.
Tomczak-Boczko Justyna, Gołębiowska Klaudia, Górny Maciej (2023), Who is a ‘true refugee’? Polish political discourse in 2021–2022, „Discourse Studies”, vol. 25(6), s. 799–822, https://doi.org/10.1177/14614456231187488
Trafas Zofia, Kamasa Victoria (2025), Dwie granice, dwa światy? Wspierana korpusowo analiza dyskursywnych reprezentacji migrantów na granicy polsko-białoruskiej i polsko-ukraińskiej, „Studia Migracyjne – Przegląd Polonijny”, nr 2(196), s. 81–104, http://doi.org/10.4467/25444972SMPP.25.014.21828
Trent John (2012), The internationalization of tertiary education in Asia: Language, identity and conflict, „Journal of Research in International Education”, vol. 11(1), s. 50–69, https://doi.org/10.1177/1475240911434339
Troszyński Marek (2024), Badania dyskursu wspomagane korpusowo (CADS) jako wsparcie jakościowej analizy treści. Studium przypadku wykorzystania programu SketchEngine w badaniach dyskursu, „Przegląd Socjologii Jakościowej”, t. XX, nr 4, s. 44–67, https://doi.org/10.18778/1733-8069.20.4.03
Winkler Ingo (2011), The Representation of Social Actors in Corporate Codes of Ethics. How Code Language Positions Internal Actors, „Journal of Business Ethics”, vol. 101, s. 653–665, http://doi.org/10.1007/s10551-011-0762-8
Zhang Jiayu, Sun Chengzhi, Hu Ying (2022), Representing victims and victimizers: An analysis of #MeToo movement related reports, „Women’s Studies International Forum”, vol. 90, 102553, https://doi.org/10.1016/j.wsif.2021.102553
Zimnica-Kuzioła Emilia (2025), Doświadczenie choroby Alzheimera jako topos w filmowym dyskursie ostatniej dekady, „Przegląd Socjologii Jakościowej”, t. XXI, nr 2, s. 45–65, https://doi.org/10.18778/1733-8069.21.2.03
Przypisy
- 1 W tekście konsekwentnie posługujemy się tym określeniem, aby uniknąć określeń związanych ze statusem prawnym, takich jak „migrant” czy „uchodźca”, a także by na pierwszym miejscu postawić podmiotowość osób, które z różnych przyczyn zdecydowały się opuścić swój kraj (por. Trafas, Kamasa, 2025: 82).
- 2 Według przyjmowanej w językoznawstwie korpusowym nomenklatury token jest pojęciem szerszym niż słowo, odnosi się bowiem do każdej pojawiającej się w korpusie jednostki innej niż spacja. Są to więc słowa, znaki interpunkcyjne, liczby, skróty itp.
- 3 Podstawowe możliwości tego narzędzia przedstawia Marek Troszyński (2024).
- 4 Tłumaczenia nazw poszczególnych typów reprezentacji za Justyną Tomczak-Boczko (2025: 190–199).
- 5 We wszystkich przedstawionych tutaj wyszukiwaniach posługujemy się zestawem tagów zgodnych z tagsetem Narodowego Korpusu Języka Polskiego (Przepiórkowski i in., 2012).
- 6 W przypadku chęci modyfikacji zaproponowanych tutaj zapytań bądź problemów z działaniem sugerujemy, aby skorzystać z narzędzia AI Search w Sketch Engine, wklejając oryginalne zapytanie.
- 7 Podając przykłady, posługujemy się konsekwentnie jednymi z pierwszych przykładów z uzyskanej na platformie Sketch Engine próbki losowej. Wszystkie przykłady podane są w oryginalnej formie, bez ingerencji w zapis czy interpunkcję.
- 8 Dla każdego wyszukiwania w nawiasach podałyśmy jego częstość i częstotliwość względną na milion tokenów (pmt) w badanym przez nas korpusie.
- 9 Dla lepszego filtrowania wyników wyszukiwania przyjęłyśmy tutaj również, że nazwy grup aktorów społecznych pojawiają się w rodzaju męskim i odnoszą do osób. W przypadku poszukiwania przykładów grup kobiecych należy zmodyfikować zaproponowane zapytanie.
- 10 Z tego powodu podajemy tutaj wybrane ręcznie przykłady, a nie zrzuty ekranu jak w przypadku pozostałych wyników.
- 11 Przeszukiwanie i analizę takiego korpusu ułatwi stworzenie korpusu równoległego z niezanonimizowanym korpusem jako drugim.
- 12 Zawężenie wyników otrzymamy, jeśli skorzystamy z wcześniej zanonimizowanych plików. Wówczas wyszukiwanie będzie miało postać: [word="."][word="OSOBA"][word="."][]{0,2}[lemma="nauczyciel|lekarz|prawnik"].
- 13 W przypadku tego zapytania użyłyśmy słowa „matka” zamiast słowa „migrant”, ponieważ dla tego ostatniego nie uzyskałyśmy żadnych wyników.
- 14 Ze względu na specyfikę i trudność tłumaczenia tego typu określeń z zachowaniem odpowiedniego ładunku emocjonalnego zdecydowałyśmy się zostawić je tutaj w oryginale.