 https://orcid.org/0000-0002-8892-099X
https://orcid.org/0000-0002-8892-099XJagiellonian University in Krakow, Polandhttps://orcid.org/0000-0002-8892-099X
Independent scholarhttps://orcid.org/0000-0001-9107-0546
Humboldt University of Berlinhttps://orcid.org/0000-0001-8254-7621
Institute of Political Studies of the Polish Academy of Scienceshttps://orcid.org/0000-0002-8253-3622
Abstract:
Already in the early 1990s, one could encounter the opinion that the state in which the field of qualitative research finds itself bears the hallmarks of the ‘curse of abundance’. Since then, the phenomenon of proliferation in the field has continued to gain momentum. Due to the dynamic growth of qualitative variants of research methodologies, methods and techniques, as well as the enormous internal diversity of the field, qualitative researchers are struggling to orient themselves in the field of their own research practice. Increasingly, many researchers signal the need to systematize their knowledge of the numerous contemporary variants of qualitative research practice. This article responds to this need. It presents a model of the field of contemporary qualitative research based on the IT concept of domain ontology, developed based on a multidimensional content analysis of five dominant methodological journals presented in the form of a semantic network. The proposed model gives an insight into the essential elements of the field (epistemological approaches, data collection and analysis methods, classified into 369 ontological classes), as well as shows their clusters and inter-class relationships. It indicates the existence of three sub-fields characterized by the presence of different approaches and research methods, which differ in density and the strength of relationships. The ontological model of the qualitative research field is an important step toward the development of a domain qualitative research knowledge base, i.e., an information system organizing methodological knowledge that allows for trend monitoring, knowledge management, and effective use of knowledge in research practice.
Keywords:
meta-analysis, qualitative research, domain ontology, dictionary-based content analysis, text mining
Abstrakt:
Już w latach dziewięćdziesiątych pojawiła się opinia, że obszar badań jakościowych cierpi na „klątwę urodzaju”. Zjawisko to przybiera na sile wraz z dynamicznym rozwojem różnych wariantów metodologii, metod i technik badawczych. Badacze jakościowi napotykają trudności na różnych etapach swojej kariery i dostrzegają potrzebę uporządkowania wiedzy na temat współczesnych wariantów badawczych praktyk jakościowych. Niniejszy artykuł odpowiada na tę potrzebę, prezentując model pola współczesnych badań jakościowych, oparty na koncepcji informatycznej ontologii dziedzinowej. Model ten został opracowany na podstawie wielowymiarowej analizy treści pięciu kluczowych czasopism metodologicznych i przedstawiony w formie sieci semantycznej. Dla porządku wyodrębniono trzy obszary: podejścia epistemologiczne, metody zbierania i analizy danych, które sklasyfikowano w 369 klasach ontologicznych. Ponadto model ukazuje skupiska i zależności między tymi elementami oraz wskazuje na istnienie trzech podobszarów, które charakteryzują się różnymi podejściami i metodami badawczymi, różniącymi się gęstością i siłą zależności. Ten ontologiczny model współczesnego pola badań jakościowych stanowi istotny krok w kierunku opracowania bazy wiedzy na temat tej dziedziny. Może on służyć jako system informacyjny do organizacji metodologicznej wiedzy, monitorowania trendów, zarządzania wiedzą oraz skutecznego wykorzystania jej w praktyce badawczej i dydaktycznej, poszerzając spojrzenie na dostępne praktyki i zwiększając pewność wśród badaczy do zastosowania różnych podejść w zbieraniu danych i analizie.
Słowa kluczowe:
metaanaliza, badania jakościowe, systematyzacja wiedzy, ontologia dziedzinowa, słownikowa analiza treści
It is better to travel through a single land with
a thousand pairs of eyes than a thousand lands
with a single pair of eyes.
M. Proust
As early as the early 1990s, it was argued that the state of the field of qualitative research was the ‘curse of abundance’. ‘Researchers have never before had so many paradigms, strategies of inquiry, and methods of analysis to draw upon and utilize’ wrote Norman Denzin and Yvonna Lincoln (1994: 11) at the time. Since then, the phenomenon of proliferation in the field of qualitative research has taken hold. The creative overcoming of limitations realized during the triple crisis affecting the spheres of representation, legitimacy, and impact of qualitative research practice (cf. Denzin, Lincoln, 1994; 2005; 2011), has been accompanied by institutional pressure for innovation (Travers, 2009), resulting in the continuous development of new ways of research (Taylor, Coffey, 2009). This trend is reinforced by the penetration of qualitative methods into many different disciplines and hence contexts and areas of research. It is also reinforced by the acceleration of changes taking place in the social world, including through the development of new technologies, to which qualitative research methodology is trying to adapt. When confronted with new interdisciplinary research questions, traditional qualitative methods, born in anthropology and sociology, undergo adaptive modification or radical change (Wiles, Crow, Pain, 2011). The proliferation of the very ways in which qualitative research is conceptualized and carried out is also accompanied by an exponential growth of knowledge about it, particularly in the form of scientific articles published in dedicated journals, the growth of which has been observed since the beginning of the 21st century (Atkinson, 2005). New and numerous testimonies of individual qualitative research practices confirm the premise that the open nature of a qualitative research project resists relentlessly trying to capture it with a single, simple paradigm (Denzin, Lincoln, 2011). They also point to the increasing fragmentation of the qualitative research field, which goes hand in hand with increasing specialization in narrow sub-areas of qualitative research practice (Atkinson, 2005).
Due to the enormous internal differentiation of the field of contemporary qualitative research and the accompanying terminological confusion (Knoblauch, Flick, Maeder, 2005), qualitative researchers struggle to orient themselves within the domain of their own research practice. Following Paul Atkinson, one may say that the ‘current state of qualitative research and research methods is confused’ (Atkinson, 2005). This opinion is shared by editors of methodological journals (see, among others, Chenail, 2009) and authors of analyses synthesizing qualitative research findings (see, among others, Sandelowski, Barroso, 2003). They call attention to the low level of methodological awareness found among qualitative researchers. This is evidenced by, among other things, a lack of coherence between the research questions posed (implying the utilization of certain methodological strategies) and the strategies actually applied; between the methodological trends and research methods to which the practitioners refer and the methodological solutions which are, in fact, implemented; and between the methodological orientations declared (assuming the presentation of results in a specific manner) and the results which are finally described (Sandelowski, Barroso, 2003; Chenail, 2009). The need to deal with the negative consequences of the ‘curse of abundance’ in the field of contemporary qualitative research is also signaled by researchers themselves. During professional conferences, they are more and more often addressing topics directly related to the issues of organizing knowledge about different variants of qualitative research practice and reducing the complexity of the semantic space of the field of contemporary qualitative research. They also complain about the lack of established and widely accepted criteria for evaluating qualitative research procedures and results (Ravenek, Rudman, 2013). Moreover, the increased methodological awareness of qualitative researchers gains relevance in the face of the contemporary debate on standards for practicing evidence-based science, which questions the credibility of research findings conducted by means of qualitative methods and, consequently, questions their social utility as unhelpful to policy makers (Lester, O’Reilly, 2015). The basis for formulating arguments to defend the status of qualitative research practice should be an in-depth, critical reflection on the current condition of the qualitative research field, which is encouraged by our ongoing project to develop a domain ontology of qualitative research.
This article presents a model for mapping and representing knowledge about the field of contemporary qualitative research, based on the IT-derived concept of domain ontology (Gruber, 1993; Munn, Smith, 2008), the methodology of dictionary-based content analysis (Short, McKenny, Reid, 2018) and the notion of semantic networks as a way of representing knowledge (Quillian, 1968). The term ‘domain ontology’ comes from knowledge engineering. It is used to describe an ‘explicit formal specification of the terms in the domain of discourse and relations among them’ (Gruber, 1993). Domain ontologies represent knowledge of a specific discipline or field through a specification of the ‘terms used in a […] domain, the definition of relationships among the terms, and the expression of the relationships in a hierarchical structure’ (Lim, Song, Lee, 2004). They provide a systematic account of what ‘exists’ in particular domains, expressed in a way that can be processed by information systems.
Understood in this way, ontologies form conceptual patterns that reflect the structure of domains, providing insight into their classified elements and mutual configurations. Ontologies are knowledge models with two basic characteristics: 1) they are expressed in formal languages with well-defined semantics and 2) they are based on a common, conventional understanding and definition of concepts and the relationships between them in each community. As a way of representing the semantic space of a particular domain, ontologies provide a basis for communication between researchers, fostering the formation of a coherent way of addressing its themes. The consequence of creating domain ontologies may be the construction of knowledge bases, i.e. information systems organizing knowledge, which allow for monitoring trends, managing knowledge and its effective use in research practice. The domain ontology presented in this paper was created with usage of the methodology of dictionary-based content analysis and semantic networks. To create it, we used a classification dictionary developed based on multidimensional content analysis of articles from five leading methodological journals. The dictionary contains classes of methodological objects (such as epistemological approaches, data collection and analysis methods). A semantic network (Helbig, 2006) illustrates relationships between the classes. The proposed approach to the analysis of the field of contemporary qualitative research is thus based on a system of networked knowledge representation that facilitates the analysis and presentation of the complex relations between the different elements of the field. In contrast to traditional thesauri or dictionaries, networks enable a holistic, structural view of what is happening in the knowledge field under analysis (Newman, Barabási, Watts, 2006). At the same time, thanks to the existence of a rich spectrum of metrics, we can ‘measure’ the strength of relationships between different classes of methodological objects.
We believe that the development of domain ontology – reflecting the qualitative research design – is an important step towards a digital compendium of knowledge about variants of qualitative research practices and, consequently, a platform for the exchange of experiences, leading to the improvement of research methods, as well as their better transparency, and thus to an increase in confidence in the results of qualitative research. Our project is part of a more general trend of systematizing knowledge (exemplified by Duevel, 2019) and interdisciplinary meta-reflection on practicing science (known as ‘science of science’). It is based on the analysis of large data sets, with the aim to learn the rules and regularities that govern the functioning of science. The subject of research in this area is productivity and creativity in science, as well as how the field of research is shaped, what research topics emerge, which methods and techniques are most often used in it, and which only marginally (Wang, Barabási, 2021).
The article consists of a presentation of the methodology of the process of creating a domain ontology, starting with building a corpus of articles, extracting methodological phrases, developing and implementing a classification dictionary, and visualizing the relationships between the elements of the qualitative research field highlighted in the dictionary. Then, we characterize the field of contemporary qualitative research based on the interpretation of relations between the elements of the field visualized in the semantic network. The whole work ends with a reflection on the possibilities opened by the creation of a domain ontology for the methodology of qualitative research.
The adopted strategy for creating a domain ontology for qualitative research was aimed at discovering and systematizing methodological knowledge reflected in the living language used by researchers when describing their projects in articles published in scientific journals. The articles represent a variety of ways of conceptualizing and carrying out qualitative research, including those that, because of their originality or uniqueness, do not (yet) belong to the canon shaped by anthologies and textbooks. Due to their relatively short publication cycle, methodological journals are much quicker to react to changes occurring in the field of qualitative research, making it possible to spot trends not sanctioned by tradition. To a much greater extent, they also reflect the multitude of voices behind the diversity of qualitative research practice, which consists of the thoughts and actions of both authorities and novices and representatives of different disciplines.
In the process of building an ontology model of the field of contemporary qualitative research based on a multidimensional content analysis of methodological journals, we moved from traditional qualitative analysis, based on a text coding procedure, to quantitative content analysis. In our methodological approach, we combine corpus linguistics methods with computer-assisted qualitative data analysis (CAQDAS), content analysis, as well as natural language processing and text mining procedures (Berry 2004; Wiedemann, 2013; Bryda, Tomanek, 2014; Bryda, 2014; 2019; 2020). In the realm of contemporary qualitative research field, the shift from traditional qualitative analysis to a multidimensional approach combining quantitative content analysis, corpus linguistics, CAQDAS, and natural language processing (NLP)/text mining is driven by several compelling reasons. Firstly, the integration of quantitative methods addresses the limitations of manual text coding in traditional qualitative analysis, which can be subjective and constrained in scope. This shift allows for a more comprehensive and in-depth analysis of large volumes of data typically found in methodological journals, offering a broader perspective of the research field. Secondly, the use of quantitative content analysis and NLP/text mining techniques enhances objectivity and consistency in the analysis process. This is particularly important for developing a reliable and valid ontology model, as these methods help mitigate human bias and ensure uniformity in data interpretation. Efficiency and scalability are also key factors. The adoption of computer-assisted methods such as CAQDAS and NLP significantly accelerates the data analysis process, a vital aspect when dealing with extensive datasets. Moreover, these techniques excel at identifying complex patterns, trends, and relationships in text data, which might be overlooked or too labor-intensive to discern manually. Another advantage is the interdisciplinary nature of this approach. By merging corpus linguistics with CAQDAS and content analysis, the methodology benefits from a diverse range of insights, leading to a more robust and comprehensive understanding of qualitative research. Furthermore, contemporary qualitative research often involves diverse and evolving data formats. NLP and text mining are particularly adept at adapting to and analyzing these varied types of data. This adaptability is crucial for an accurate and relevant analysis in today’s fast-evolving research landscape. Lastly, the use of advanced computational techniques significantly contributes to enhancing the ontology model. These methods enable the creation of a more detailed and precise model, capturing the complexities and nuances of contemporary qualitative research. In conclusion, this transition aims to harness the strengths of both qualitative and quantitative methodologies, utilizing state-of-the-art computational techniques to enrich the depth, accuracy, objectivity, and efficiency of the analysis. This fusion is essential for constructing an ontology model that accurately reflects the intricate and dynamic nature of contemporary qualitative research. The result of this fusion is the ontology classification dictionary of epistemological approaches and methods for collecting and analyzing the data described in the analyzed articles, which was then used to develop a domain ontology and visualize the relationships between ontology classes. The creation of the dictionary and ontology was a process consisting of four steps according to the following blueprint.
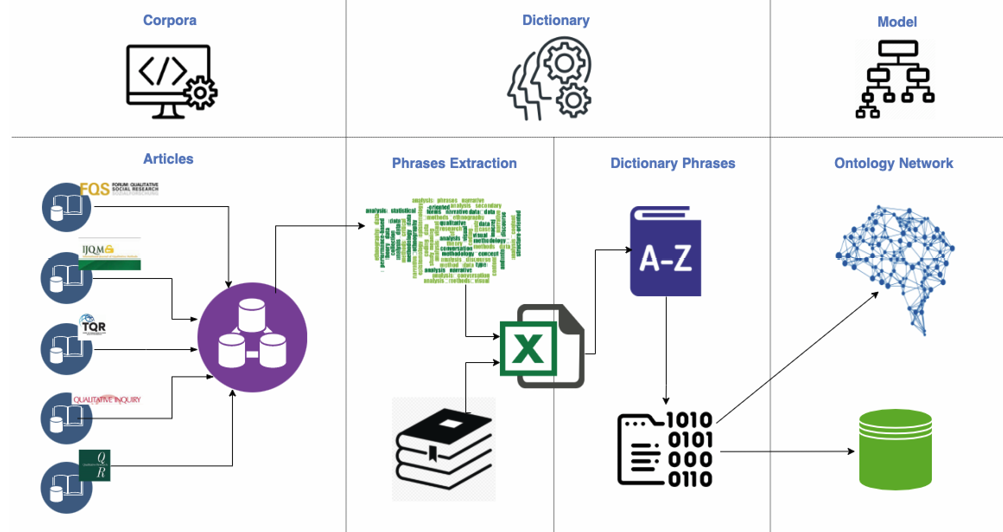
Figure 1. Blueprint for building the classification dictionary and the domain ontology model
Source: Authors’ own study.
The first stage focused on creating a corpus of texts. Subject to analysis were scientific full range of articles published between 1990 and 2020 in five leading methodological journals: “Qualitative Inquiry” (QI), “Qualitative Research” (QR), “International Journal of Qualitative Methodology” (IJQM), “The Qualitative Report” (TQR) and “Forum: Qualitative Social Research” (FQSR). The selection of journals for this study was guided by their distinctive role and position in the global community of qualitative researchers, as evidenced by high Impact Factor values, as well as the interdisciplinary nature of these journals. This approach was intended to mitigate potential biases associated with discipline- or subject-specific methodologies. Such situations may be common in more specialized journals such as “Qualitative Health Research” or “Qualitative Research in Education|. By focusing on these selected journals, our intention was to capture a comprehensive understanding of how qualitative research is conceptualized and practiced worldwide in the qualitative research community (Archibald et al., 2015). The scope between 1990 and 2020 has been demarcated by the year in which the oldest among the analyzed journals, TQR, was established and the year when the data collection stage within our project ended.
The raw files downloaded from the journals’ servers were converted to the txt. format. In the corpus, metadata such as publisher, journal title, year of publication, and author were entered for each article. We divided the article structure into title, abstract, keywords, body (the content of the article), and bibliography/references. We selected only articles written in English due to the need to standardize the corpus and the subsequent coding procedure. The original corpus contained 8,267 articles. The exclusion of non-English texts from the analysis and the lack of access to the content of the oldest articles reduced the corpus to 7,524 articles. Finally, after applying the criteria of analytical inclusion: complete texts, scientific articles, we omitted reviews, editorials, conference reports, and poems. Other types of content serve different purposes, such as evaluation, opinion, or artistic expression. The corpus includes 7,281 articles from the five journals mentioned above.
Table 1. Journal corpora structure
| Journal | Years | Articles | % Articles |
|---|---|---|---|
|
TQR |
1990–2020* |
2,371 |
32.6% |
|
FQS |
2000–2020 |
1,140 |
15.7% |
|
IJQM |
2002–2020 |
927 |
12.7% |
|
QR |
2001–2020 |
1,114 |
15.3% |
|
QI |
1995–2020 |
1,729 |
23.7% |
|
Total |
1990–2020 |
7,281 |
100% |
* No articles were published in 1993, 1998 and 1999.
Source: Authors’ own study.
In the second stage, we drew a sample of articles (a third of the texts in the corpus)[2] and then read the selected articles and manually extracted phrases that were linguistic indicators of epistemological approaches, data collection and analysis methods. These are, on the one hand, the proper names of approaches and methods (e.g., ‘digital ethnography’, ‘dyadic interview’), and on the other hand – linguistic expressions indicating their use (e.g., ‘interview design’; ‘interview protocol’; ‘ethno-diary’). Owing to the sample, we also obtained linguistic patterns that we used in the process of automatic indexing and coding of the entire corpus of articles while checking the contexts in which the phrases occurred. The process of manual extraction of phrases took about a year and a half, as team members had to read whole texts and select phrases from them that could be considered methodological. We used two-step collaborative validation process. Manually extracted phrases were sent to the coordinator and he created a database from them. The database was then subject to cleaning. The team of coders worked on collections of assigned articles using the Antconc, the QDAMiner, and the Wordstat software, as well as the Django database specially created for the project. Then, using the linguistic patterns for phrases obtained in the previous stage, the articles were subjected to linguistic analysis using Sketch Engine software, the Oneclick. The aim of this analysis was an in-depth, automatic extraction of additional phrases and linguistic indicators. Finally, all phrases were analyzed by the research team in the context of their use in the articles (KWIC/KPIC) before being included in a dictionary classifying elements of contemporary qualitative research. The combination of manual and computer-assisted work by the research team and coders was an important step toward building the dictionary and creating a domain ontology. It made it possible to increase the face validity of the classification dictionary, its subsequent validation, and the creation of search patterns for methodological expressions. Thus, through the extraction and revision of phrases, a viable collection of proper names and linguistic indicators of specific research practices cited by article authors was created. The phrases extracted from the articles, in line with the notion of triangulation, were supplemented with linguistic phrases and expressions present in leading book publications on qualitative research methodology from the period 2006–2020 (see Appendix). This work was regarded as a complementary effort to the existing dictionary, aiming to incorporate instances of research practices that were referenced in the index of textbooks. These phrases had not yet been directly observed within the articles, and their inclusion in the dictionary served the purpose of preventing their omission or misclassification. In anticipation of their potential emergence in future articles, provisions have been made to accommodate their incorporation into the dictionary. Consequently, the resultant classification dictionary became an exhaustive collection of methodological language objects present in the analyzed corpus.
In our research approach, as detailed in the paper, we meticulously implemented a series of strategies to establish the credibility of our document analysis process and to ensure that biases are effectively avoided, leading to conclusions. We maintained a high level of methodological clarity. This was achieved by clearly outlining the methods used for document selection, analysis, and interpretation, making our research process open for scrutiny and validation. Understanding the importance of varied perspectives, we incorporated a full range of document from journal sources. This diversity helped mitigate the risk of bias that might arise from relying on a single journal. In addition, we employed cross-verification techniques across multiple documents to bolster the reliability of findings, identifying and correcting any inconsistencies or biases presented in individual documents. We assess the credibility, context, purpose, and potential biases of the authors of each document we analyze. Reflexivity is a key practice in research approach. We continuously reflected on and critiqued our own biases and how they might influence our analysis, ensuring a more objective approach. Peer review and feedback are integral components of our methodology. We subjected our analysis to scrutiny in identifying potential biases and blind spots. Researcher’s triangulation and using multiple text analysis methods is another strategy we employed to confirm findings and strengthen the validity of this study. We consistently and sequentially applied analytical frameworks across all documents to maintain objectivity. Through these rigorous and methodical strategies, we ensure that our research not only addresses potential biases in document analysis but also enhances the credibility and persuasiveness of our conclusions, making a significant contribution to this field of study.
Building the classification dictionary of the elements of the qualitative research field was the final analytical step. It provided a bridge between the research practices described in the articles and the ontological system of knowledge representation of the field of contemporary qualitative research. In the process of building the classification dictionary, we adopted an inductive-deductive approach – we undertook a structured approach, blending inductive and deductive methodologies. The work proceeded in several stages, providing a systematic framework for representing elements of qualitative research.
The construction of the dictionary began with a detailed review of all the linguistic phrases and expressions collected in the previous phase (there were nearly 25,000 of them), which allowed us to become fully acquainted and familiar with the richness of the language of qualitative research methodology. By inductive analysis we identified key concepts and themes emerging directly from the data, leading to the creation of dictionary preliminary categories.
Then, we then refined these categories deductively, applying theoretical context to ensure systematic structuring frameworks. We proceeded to a compact division of phrases into sets. We distinguished seven main ones, three each in data collection and data analysis, and one referring to the paradigm adopted in the research (epistemological approaches) (see Table 2).
Lastly, guided by the need to reflect the research process in the domain ontology, we decided to choose three aspects: epistemological approaches and data collection and analysis methods. This choice was also determined by the high fragmentation and diversity of the elements of the qualitative research field, which made the subsequent use of the glossary and interpretation of the results difficult.
The epistemological approaches referred to broader paradigms of methodological thinking and philosophy of science (e.g. materialism, interpretivism), within which were located research methods relating to how data was collected (interview, ethnography) and related methods of data analysis (thematic analysis, content analysis). This division enabled the creation of a general classification framework for the dictionary, the detailed verification and further ordering of phrases, whose three sets (metaclasses in the dictionary) and subsets (classes in the dictionary) mentioned above made up the ontological picture of the field. The review of the extracted phrases within the sets representing data collection and analysis methods showed that they were characterized by polysemy and had different designations related to their use in articles. The phrases collected in this set referred to the proper names of methods or types of methods, the object of research, the type of research material generated by specific methods, the designation of products of the research process, forms of dissemination of research results, as well as research activities related to the application of a given method. To avoid polysemy, we decided to introduce an indirect division of phrases in the dictionary into three ontological categories: methods, forms, and phrases. The methods category includes explicitly expressed proper names of research methods (e.g., ‘semi-structured interview’) or their types (e.g., ‘arts-based methods’). The forms category includes the names of both the object of study and the research material (e.g., ‘narrative’, ‘biography’), or the research product or method of presenting the results (e.g., ‘film’, ‘drawing’). Phrases, on the other hand, are linguistic expressions that have specific designations related to the methods in question, but do not explicitly name them (e.g., ‘interview protocol’, ‘autoethnographic reflection’).
Following the logic of ontology creation, we also performed semantic reduction within classes and subclasses. In cases of synonymic similarity between phrases representing the same methods of data collection or analysis, we chose the name of the class more frequently occurring in the corpus (e.g., ‘conversation analysis’ instead of ‘conversational analysis’; in this case, the phrase ‘conversational analysis’ became a linguistic indicator of the class ‘conversation analysis’). The final division of all methodological phrases expressed in the structure of the classification dictionary reflects the order of generalization from the most general assignments at the level of metaclasses (set of epistemological approaches, set of data collection methods, set of data analysis methods), through classes (types/types of approaches and methods), to the most specific subclasses (subtypes) and their linguistic indicators (indexed phrases) present in the articles (Figure 2).
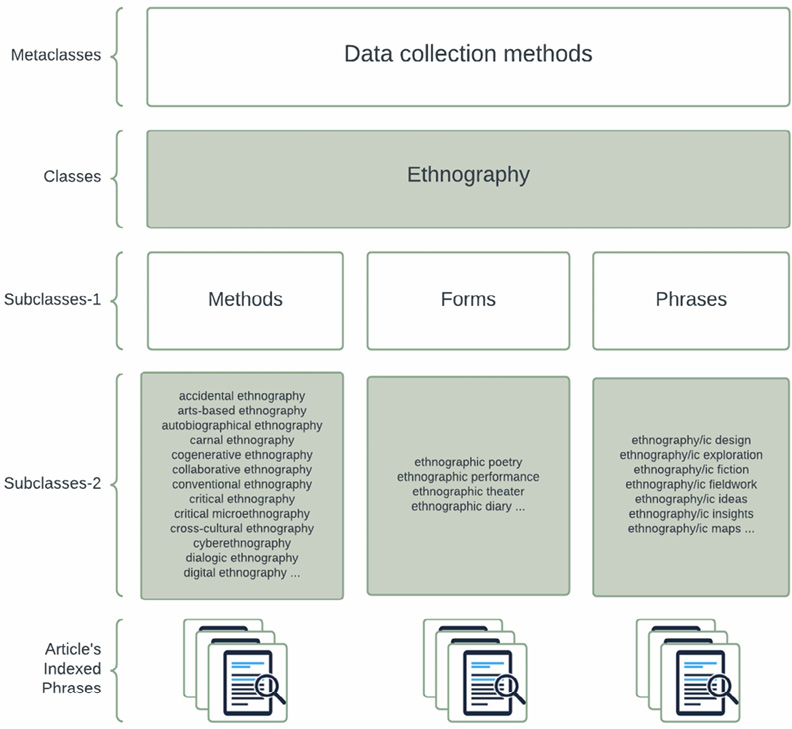
Figure 2. Classification dictionary structure
Source: Authors’ own study.
The basis for the classification of each phrase was its morphosyntactic structure. Most commonly, a phrase is an adjective-noun or noun-noun combination. Before being assigned to a given class or subclass, each phrase was checked from a semantic point of view. We checked definitions and the linguistic context in which the phrases occur in articles and discussed in the project team the belonging of particular approaches and methods to particular ontology classes. Similarly, in the process of conceptualizing classes and subclasses, we worked interactively in teams, verifying through discussion any ideas for creating separate sets and subsets and classifying individual phrases. In the end, we obtained 369 ontology classes, 1,523 subclasses, and 2,452 indexed phrases in a dictionary classifying the basic elements of the qualitative research field.
Table 2. Ontology dictionary metaclasses
| Metaclasses | Classes |
|---|---|
| Data analysis coding | 61 |
| Data analysis methods | 128 |
| Data analysis software | 42 |
| Data collection type | 36 |
| Data collection methods | 55 |
| Data collection sampling | 6 |
| Epistemological approaches | 41 |
| Total | 369 |
Source: Authors’ own study.
These involve both conceptual work (designing the dictionary and class structure) and operational work on the dictionary (reconstructing/indicating relationships between classes, searching for linguistic indexes). The most difficult was to design the structure of ontology classes, to define them and then to group them according to the principle that each object was an index of a specific method. In practice, we had to deal with a huge amount of data: articles, which had to be selected and browsed, and phrases (language expressions), which had to be extracted, cleaned, and organized manually in the dictionary. At the same time, in accordance with the assumption of not relying on classification schemes present in methodological literature, we looked for a data-embedded, summary way of ordering the structure of the classes. We verified the bottom-up created structure analytically, moving from metaclasses, through classes to linguistic phrases (from sets to the objects belonging to them). Yet another challenge was to find a computer software to support the creation of the dictionary, which would allow the research team to work synchronously, given its spatial dispersion and different IT and analytical competencies. In the end, a spreadsheet proved to be the most functional tool. It enabled teamwork in the period marred by the COVID-19 pandemic, compiling and uploading data, organizing phrases after extraction, and working on ontology classes. Working systematically with the spreadsheet and reading the phrases was an arduous task requiring patience and regularity. The plurality of attitudes and thinking styles of the project team members required a lot of discussions on the final structure of the classes and the dictionary itself. Phrases and classes were repeatedly reviewed in task subgroups and collectively before finding their place in the dictionary. For the more controversial examples, we discussed them as a team, checked the contexts of usage in the corpus and the existing definitions. It took a very long time to prepare the data for analysis due to the diversity of templates used by the publishers, the impossibility of converting files or removing information noise (meta-tags hidden in the text). Therefore, at this stage of data pre-processing, we used Python natural language processing scripts prepared just for this purpose. The conceptual and analytical work on the classification dictionary and its validation and testing took almost three years. The developed classification dictionary is an analytical model that can be used for a systematic study of relations between ontology classes, as well as for monitoring the dynamics of the field of qualitative research (studying changes in relationships over time). Increasing knowledge and competence in qualitative research methodology is an undisputed advantage. Working with linguistic phrases and expressions for many months has allowed us to become familiar with both the rich vocabulary used by qualitative researchers and the dominant methodological language in the field, which has contributed to an increased awareness of the diversity of qualitative research practices. An extremely enriching experience in the work of the research team – made up of people coming from three different research centers – was the clash of habiti and points of view concerning the knowledge of methods or forms of qualitative research, and, consequently, negotiating their final place in the dictionary.
Just like creating a codebook, building a classification dictionary is an extremely important step in text data analysis. A well-designed codebook or dictionary determines how subsequent stages of analysis and the interpretation of its results will proceed. A classification dictionary is just a transitional stage in text data analysis and the creation of a domain ontology. The value of the dictionary as an analysis tool is determined only by its use regarding a corpus of articles. However, this use requires reflection on how ontology classes are present in articles. Therefore, the most difficult issue in the process of developing an ontology for contemporary qualitative research was to find a way to represent the classes in individual articles and in the corpus as a whole. Text representation is one of the key problems of natural language processing, text mining, and Information Extraction and Retrieval (IER). It involves searching for a suitable numerical representation of the meanings present in the processed text to make them mathematically computable and transformable. In the case of creating an ontology for the field of contemporary qualitative research, this concerns finding a way to represent the presence of methodological classes in the article and in the entire corpus. Based on our own analytical experience and literature review on text representation methods (Jurafsky, Martin, 2009), we decided to use in the project the TF-IDF method, which is used to calculate the weight of words/phrases based on the number of their occurrences. TF-IDF is the product of two factors: the frequency of a word/phrase in a document (TF, Term Frequency) and the inverse frequency of the word/phrase in all documents (IDF, Inverse Document Frequency). In the TF-IDF model, each document is represented by a vector consisting of the weights of words/phrases present in that document. In simple terms, a document is checked for the individual words/phrases present in it. As a result, ‘significance vectors’ are created to determine the subject matter of the document. This approach makes it possible to determine the significance of a word/phrase in the context of its occurrence and to eliminate confusion regarding the classification of e.g. homonyms, i.e. identical-looking words with different meanings. In our case, the TF-IDF value refers to the occurrence of a methodological class. The more often a class occurs in the corpus, the lower the IDF score will be. With the TF-IDF statistic, we obtain the weight (relative frequency) of the class occurrence in the analyzed set of documents.
In the domain ontology project, we used n-gram linguistic expressions as indicators of epistemological classes, research method classes, and analytical method classes. N-grams, sequences of ‘n’ items from a text or speech, are adept at capturing the nuanced contexts that differentiate various academic methodologies and theories. This approach enhances the precision of categorizing text into specific domains, particularly useful in the complex and structured language of academic discourse. Moreover, n-grams facilitate the recognition of recurring linguistic patterns, essential for identifying consistent themes across a range of documents. This capability is particularly advantageous for automated text analysis, enabling efficient handling of large datasets. Additionally, the flexibility of n-grams to adapt to the specific terminologies of different research fields makes them an invaluable tool in building a robust and comprehensive ontology that accurately reflects the diverse methodologies and analytical approaches in various academic disciplines. By using TF-IDF, we obtained measures being indicators of the presence of specific ontology classes. In this way, we were able to create a dictionary representation of knowledge about the field of qualitative research that reports the frequency of occurrence of an ontology class both in an individual article and in a corpus, while at the same time taking into account the appropriate balance of the importance of a given class (thematic saturation) in the whole corpus. TF-IDF shows how a given article presents itself against the entire corpus. It allows comparing the saturation of an article with classes and determining its thematic scope in relation to other articles. It can also be used to group articles according to their thematic similarity. In the process of creating the domain ontology, we used TF-IDF not only to determine the saturation of articles with ontology classes or their thematic scope, but also to create a matrix of class representation in articles and in the whole corpus (article × class). We then transformed it into a similarity matrix (class × class), so as to reconstruct the relationships between the distinguished classes: paradigms, research methods, and analytical methods. Finally, we used the method of network analysis to represent the relationships between the ontology classes within the corpus.[3] The network is a form of visual representation of the domain ontology, a map of the relationships between classes as summary indicators of what is happening in the field of contemporary qualitative research.
The first step in creating a visual representation of the domain ontology was the construction of a bi-modal network matrix. In columns, this matrix contained 185 distinguished classes of epistemological approaches, data collection methods and data analysis methods, and in rows – 7,281 articles from five journals. The network was then subjected to an affiliation procedure, i.e., the decomposition of bimodal networks into unimodal (1-mode) ones. It consists in transforming the matrix in such a way that it shows the relationships between the distinguished classes by their weighted distribution in the articles. The most commonly used algorithm here is the sums of cross products algorithm, which performs multiplication in the columns of matrices of the values of node A with node B and summing up the results. However, this procedure can lead to the overestimation of some node links (i.e., despite using the TF-IDF vector in the procedure to weight the classes in the articles, they would tend to cluster in certain journals). This is because some journals are thematically closer to a given ontology class. For example, in the journal “Forum: Qualitative Social Research”, much more was written about ‘metaphor analysis’ and ‘textual analysis’ than in other journals. Such a network will tend to concentrate this subject matter only in that journal. Therefore, we used the Jaccard index, which weighs each link against the overall distribution of participation of the class across all journals. Let us assume that the strength of the links between ‘metaphor analysis’ and ‘textual analysis’ is 10 / (120 + 82 – 10) = 0.05, where the denominator is the sum of the occurrences of both classes minus the number of occurrences that are common to both classes (in the same journals). The result is a unimodal weighted network showing the distribution of co-occurrences of each class in the corpus. The unimodal network transformed in this way was then used to create a static, visual representation of the domain ontology of contemporary qualitative research of the five analyzed methodological journals from the last 30 years (Figure 3).
The network representation of the ontology of the field of contemporary qualitative research contains 185 classes. The semantic network is composed of nodes and ties.[4] Each node represents a specific ontology class. The size of a node (point) indicates the degree of links that a given class has with other classes, i.e., the number of interclass relationships in the field. The largest points are the classes most frequently co-occurring with other classes. Each link has a value, which not only reflects the fact of its occurrence, but also indicates how strongly a given class is related to other ontology classes in the corpus. Another feature of a relationship is the distance between two related classes. The further they are from each other, the lower the value of their co-occurrence in the corpus. Conversely, if two nodes (two classes) close to each other can be observed, it means that more often the classes in question co-occur in the corpus. Co-occurrence indicates that researchers exclude or combine certain epistemological classes, collection method classes, and data analysis method classes. The distance between classes also shows how classes combine into specific subsets, forming clusters of approaches and methods used in qualitative research practice. An example of such a compact cluster is the linkage of classes of three data collection methods: interview, narrative methods, and writing methods. Another example is the clustering of the mixed methods class of data collection and the classes of data analysis methods, i.e., content analysis, statistical analysis and process analysis.
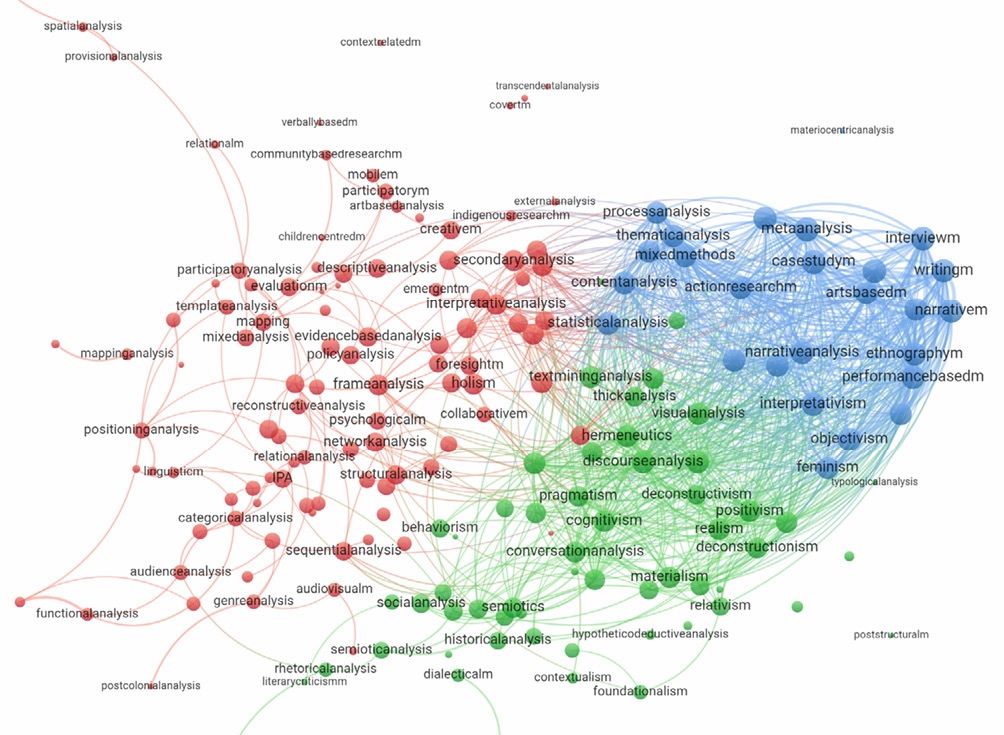
Figure 3. Network representation of the domain ontology
Source: Authors’ own study.
The analysis of the semantic network shows that contemporary qualitative research consists of three subfields (clusters) characterized by different degrees of internal clustering, i.e., relationships between ontology classes occurring in them. In the network, we have marked in blue the clusters with the highest clustering, in green those with intermediate clustering, and in red those with the lowest clustering. The blue cluster contains 26 ontology classes. These are mainly long-established research practices that constitute the canon of contemporary qualitative research methodology, are widely known and are often described in textbooks and the analyzed articles. This cluster is dominated by four sets. The first is classes of data collection methods: interview, writing as a method, narrative methods, art-based research, case study, and ethnography. The second are classes of data analysis methods: content analysis, meta-analysis, process analysis, and statistical analysis. The third are epistemological classes, i.e., interpretivism, phenomenology, feminism, and objectivism. The fourth cluster consists of meta-analysis and case study classes. When studying these clusters, attention should be paid to the total strength of the interclass links which shows that these classes co-occur with one another in the analyzed articles.
The green cluster is formed by 56 ontology classes. Let us highlight some of them: discourse analysis, post-structuralism, cognitivism, or ethnomethodology. Conversational analysis and the paradigm of relativism also stand out. The latter has weak ties with foundationalism, a view that holds that there exist underlying judgments that are the foundation of cognition and that do not require justification through other judgments. So relativism, at least formally, will stand in opposition to this approach. Our study shows how opposing paradigms are used in texts and whether they are often spoken of in terms of their opposites. It is also worth tracing other nodes in the cluster, noting the strength of their connections to particular classes. For example, of great interest is the configuration of the feminist method, which belongs to the red cluster but at the same time is very strongly associated with the blue one. Despite belonging to a particular cluster, the feminist method is not strongly embedded in it and is also related to the classes of the green and blue clusters. By simultaneously tracking class configurations at two levels: global (the whole network and clusters) and individual (particular classes), one can extract useful information from the presented network. The red cluster contains 103 ontology classes, with the lowest density of relationships. It contains diverse classes that are not well-established in the world of qualitative research. This cluster is the most open of all to connectivity variation, suggesting that it is also open to innovative classes of data collection and analysis methods. In this cluster, imagination suggests potential connections. Can framework analysis be linked to network analysis? As one can see by following the connections of network analysis, it is close to structural analysis, but it is not mentioned in relation to text mining analysis, which is also in this cluster. Instead, the latter is strongly associated with content analysis, which, in turn, is associated with the ‘mixed methods’ class. All these connections are quite intuitive and reveal a specific ‘chain’ of the co-occurrence of classes in texts. At the same time, the interested reader can focus their attention on links that are weak or do not yet exist to discover potentially useful and innovative links.
It is also useful to understand the relationship between clusters and the classes (nodes) present in the network.[5] Notably, the blue cluster has a strong relationship with the green cluster (the density of links). For example, methods (blue cluster) such as interview and narrative methods are with paradigmatic nodes (green cluster), such as deconstructivism, hermeneutics, materialism, positivism, or realism. For example, constructivism from the green cluster (visible in the online version of the network) is very much linked to classes from the blue cluster. This will, therefore, point to the inspiration of constructivism as some deeper way of understanding science and, as a result, qualitative research methodology. Similarly, visual analysis, hermeneutics, and discourse analysis (from the green cluster) are all related to the main classes from the blue one. The position of deconstructivism is surprising. It is not as popular as it might seem. Between the green cluster, where deconstructivism can be found, and the blue one, there is only a link to narrative analysis, feminism, and interpretivism. Much more strongly, deconstructivism is embedded in the setting of classes from its cluster: poststructuralism, materialism, and discourse analysis. This suggests that this class has not yet been well-operationalized in terms of methods and is still only used as some theoretical inspiration.
The red cluster has denser connections to the blue cluster than to the green one. Its openness to connectivity variation shows that it is oriented toward innovation in combination with data collection and analysis methods. One of the central classes in this cluster – phenomenological analysis – is not related at all to the central classes of the blue cluster, but to its periphery – processual analysis, thematic analysis, comparative analysis, performative methods and meta-analysis. The same is true of another class central to the red cluster, namely interpretive analysis. It forms a strong link with the classes in the green and blue clusters. This class is, therefore, strongly embedded in data collection methods, analysis methods, as well as paradigms. On the other hand, its membership in the relatively inclusive red cluster makes it open to any innovative modifications.
The blue cluster is very strongly linked to the green one in the strategy area, and its links to the red cluster are in the analysis area. The category of mixed methods sits close to the red and blue clusters, showing links to many modes of analysis, while objectivism is intriguing as it appears very close to interpretivism and feminism.
By utilizing qualitative domain ontology, researchers can overcome the challenges of information overload and information fragmentation in qualitative research. The ontology serves as a centralized repository of knowledge, allowing researchers to efficiently access and navigate relevant information, thereby streamlining their research process and saving valuable time and effort. The application of qualitative domain ontology promotes the adoption of standardized research practices and ensures consistency in qualitative research methodologies. Researchers can refer to the ontology to understand best established practices, avoid redundant efforts, and build upon existing knowledge. This standardization fosters a shared understanding and common language among qualitative scholars, facilitating collaboration, knowledge exchange, and the coherent development of the field. To summarize, we present six scenarios for the usage of qualitative domain ontology:
Researchers from different disciplines come together to work on a complex qualitative research project. Owing to the utilization of qualitative domain ontology, they have a shared understanding of research practices and terminology. This common foundation fosters effective communication, promotes interdisciplinary collaboration, and enables the seamless integration of diverse perspectives. The researchers leverage the ontology to organize and align their methodologies, which leads to a comprehensive and rigorous study that produces valuable insights.
A group of qualitative researchers regularly updates the qualitative domain ontology with new research practices and methodologies that have recently emerged in the field. This ongoing effort allows them to identify and highlight emerging trends and innovative approaches. As a result, researchers across the globe consult the ontology to stay informed about the latest developments, enabling them to adapt their research practices accordingly and contribute to the advancement of qualitative research.
A researcher publishes a qualitative study accompanied by an ontology-based appendix. The appendix provides a detailed description of the research process, including data collection methods, analysis techniques, and underlying assumptions, all organized within the ontology’s structure. This transparent documentation enhances the study’s replicability, allowing other researchers to follow the same procedures and validate the findings. The ontology-based appendix serves as a valuable resource for researchers seeking to understand and replicate the study’s methodology.
A team of qualitative researchers regularly analyzes the qualitative domain ontology to identify patterns and trends in research practices. By observing changes and developments in the ontology over time, they notice a shift toward the incorporation of innovative data visualization techniques in qualitative analysis. Armed with this insight, the researchers anticipate that data visualization will become an increasingly prominent aspect of qualitative research methodologies. They begin to explore and incorporate these techniques into their own research, staying at the forefront of methodological advancements.
Scenario 5: Streamlined Qualitative Research Education
A university integrates the qualitative domain ontology into its curriculum for qualitative research methods. Students studying qualitative methodologies and data analysis have access to a structured and comprehensive knowledge base. The ontology serves as a guide, enabling students to navigate different research practices, understand their conceptualization and operationalization, and explore the interconnectedness of various methodologies. As a result, students gain a deeper understanding of qualitative research and are better equipped to apply appropriate methodologies in their future research endeavors.
A funding agency is seeking research proposals that address complex social issues from the qualitative perspective. By utilizing the qualitative domain ontology, the agency can clearly identify and evaluate proposals that demonstrate a strong understanding of qualitative research practices. The ontology provides a standardized framework for assessing the quality and rigor of proposed methodologies. This alignment enables the agency to fund projects that have a solid methodological foundation, leading to impactful and interdisciplinary research outcomes.
Qualitative domain ontology serves as a powerful tool for discovering new qualitative research practices and data analysis approaches. By organizing present-day knowledge, articulating erudition, shaping a consistent system of knowledge representation, and facilitating communication among qualitative scholars, the domain ontology thinking enables the cumulative development of methodological knowledge. It enhances research procedures, promotes transparency, and contributes to a coherent image of the field. Moreover, qualitative domain ontology facilitates the management and use of information, improves qualitative research education, and enables researchers to follow and predict methodological trends. Embracing qualitative domain ontology as a guiding framework empowers researchers to push the boundaries of qualitative research and drive its continued evolution and innovation.
Domain ontology promotes the development of methodological awareness and ‘being up to date’ in the field of one’s own research practice through the discovery of the patterns of methodological conduct present in the individual acts of implementing qualitative research practices. Domain ontology is a response to the manifestations of the ‘curse of abundance’ observed in the field of contemporary qualitative research: the crowding of research and analytical methods/techniques, the exponential growth of methodological knowledge, the fragmentation and thematic specialization, and the terminological chaos. The distinguishing feature of the method of systematizing knowledge on qualitative research practices and their variants adopted in this article is the interdisciplinary methodology of mixed content analysis and text mining based on combining inductive and deductive thinking embedded in a living scientific language. The classification dictionary, to which we have given considerable attention in this article, is a necessary and crucial step toward systematizing and representing knowledge about these practices. It serves both to ensure terminological consistency and explore the relationships between ontology classes (nodes in the network), and then to analyze and uncover the internal dynamics of the field of qualitative research.
Our study is advantageous for academic knowledge development as well as practical applications. By representing classes in articles, we can illustrate the diversity of qualitative research methodologies. In this multiplicity of ontology classes and the existing relationships between them, there emerge patterns of connections between approaches and methods of data collection and analysis. The result is a coherent picture of a seemingly incoherent field, which once again shows that insightful analyses on large datasets make it possible to see order in chaos. What appears disordered from a subjective point of view (the course of abundance) is framed within a clear, albeit complex, picture of qualitative research practices (domain ontology). One begins to realize that what appears to be a space of individual choices about combining approaches and methods of data collection and analysis is, in fact, a set of patterns accumulated over the years. By systematizing knowledge of these patterns of conducting research, one can understand and shape the process of cumulative development of these patterns contributing to the improvement of existing qualitative research methodologies. However, ontology allows us not only to become aware not only of the past, but also to anticipate some connections and show possible links. Ontology is not just a strictly academic exercise but, rather, work on knowledge consciousness that allows researchers from sometimes very distant regions of the field to come together, recombining the methods and techniques used, and ultimately innovating. We hope that the consequence of developing domain ontologies will be the building of a knowledge base, i.e., an information system organizing knowledge, which will allow monitoring methodological trends, managing knowledge, and using it effectively in research practice. Finally, academics can use ontologies as a teaching tool to facilitate visual orientation in the complexity of methods, techniques, and paradigms. The map provides the opportunity to trace the relationships between different classes, making it easier to see dominant ones surrounded by those that may be considered peripheral. Having in sight the whole map instead of an encyclopedic description of methods, as used in traditional propaedeutics, offers the opportunity to see important relationships between classes.
The interdisciplinary methodology we have developed for systematizing and representing knowledge, based on domain ontology, a classification dictionary, and knowledge mapping – a network representation of ontologies – represents a first step toward systematizing knowledge about the field of contemporary qualitative research practices of the last 30 years. However, it is a static picture that requires both deeper insight and a broader view. The development of domain ontology is a long-term project that requires further, more complex activities, i.e., a continuous expansion of the corpus of analyzed articles (e.g., medical, health, pedagogical, and management sciences), the automation of procedures for the extraction and discovery of new classes in the dictionary, the construction of a complex analytical model using natural language processing, but, above all, a study of the nature of the relationships between ontology classes, the dynamics of the field, and development trends. Ultimately, we also want to enrich our ontology with research topic classes. It is our belief that such a comprehensive combination of research topic classes and data collection and analysis methods as well as epistemological approaches reflects a real picture of what is happening in the field of contemporary qualitative research.
Cytowanie
Grzegorz Bryda, Joanna Gajda, Natalia Martini, Daniel Płatek (2024), Domain Ontology: The New Method of Mapping the Field of Qualitative Research Practices, „Przegląd Socjologii Jakościowej”, t. XX, nr 2, s. 118–141, https://doi.org/10.18778/1733-8069.20.2.06
Archibald Mandy, Radil Amanda, Zhang Xiaozhou, Hanson William (2015), Current Mixed Methods Practices in Qualitative Research: A Content Analtextysis of Leading Journals, “International Journal of Qualitative Methods”, vol. 14(2), pp. 5–33, https://doi.org/10.1177/160940691501400205
Atkinson Paul (2005), Qualitative Research – Unity and Diversity, “Forum Qualitative Sozialforschung/Forum: Qualitative Social Research”, vol. 6(3), https://doi.org/10.17169/fqs-6.3.4
Bryda Grzegorz (2014), CAQDAS, Data Mining i odkrywanie wiedzy w danych jakościowych, [in:] J. Niedbalski (ed.), Metody i techniki odkrywania wiedzy. Narzędzia CAQDAS w procesie analizy danych jakościowych, Łódź: Wydawnictwo Uniwersytetu Łódzkiego, pp. 13–40.
Bryda Grzegorz (2019), From CAQDAS to Text Mining. The Domain Ontology as a Model of Knowledge Representation About Qualitative Research Practices, [in:] P.A. Costa, L.P. Reis, A. Moreira (eds.), Computer Supported Qualitative Research, New Trends on Qualitative Research, Berlin–Heidelberg: Springer, pp. 72–88, https://link.springer.com/chapter/10.1007/978-3-030-31787-4_6 (accessed: 1.09.2023).
Bryda Grzegorz (2020), Whats and Hows? The Practice-Based Typology of Narrative Analyses, “Przegląd Socjologii Jakościowej”, vol. XVI, no. 3, pp. 120–142, https://doi.org/10.18778/1733-8069.16.3.08
Bryda Grzegorz, Tomanek Krzysztof (2014), Od CAQDAS do Text Miningu. Nowe techniki w analizie danych jakościowych, [in:] J. Niedbalski (ed.), Metody i techniki odkrywania wiedzy. Narzędzia CAQDAS w procesie analizy danych jakościowych, Łódź: Wydawnictwo Uniwersytetu Łódzkiego, pp. 191–218.
Chenail Ronald J. (2009), Communicating Your Qualitative Research Better, “Family Business Review”, vol. 22(2), pp. 105–108.
Denzin Norman, Lincoln Yvonna (eds.) (1994), Handbook of Qualitative Research, Thousand Oaks: Sage.
Denzin Norman, Lincoln Yvonna (eds.) (2005), The SAGE Handbook of Qualitative Research, Third Edit, Thousand Oaks: Sage.
Denzin Norman, Lincoln Yvonna (eds.) (2011), The SAGE Handbook of Qualitative Research, Fourth Edi, Thousand Oaks: Sage.
Duevel Casey (2019), SAGE Research Methods, “The Charleston Advisor”, vol. 19(4), pp. 38–41, https://doi.org/10.5260/chara.19.4.38
Gruber Thomas (1993), A Translation Approach to Portable Ontology Specifications, “Knowledge Acquisition”, vol. 5(2), pp. 199–220.
Helbig Hermann (2006), Knowledge Representation and the Semantics of Natural Language, Berlin–Heidelberg: Springer Verlag.
Jurafsky Daniel, Martin James (2009), Speech and language processing: An introduction to natural language processing, computational linguistics, and speech recognition, New Jersey: Pearson Prentice Hall.
Knoblauch Hubert, Flick Uwe, Maeder Christoph (2005), Qualitative Methods in Europe: The Variety of Social Research, “Forum Qualitative Sozialforschung”, vol. 6(3), https://doi.org/https://doi.org/10.17169/fqs-6.3.3
Lester Jessica Nina, O’Reilly Michelle (2015), Is Evidence-Based Practice a Threat to the Progress of the Qualitative Community? Arguments From the Bottom of the Pyramid, “Qualitative Inquiry”, vol. 21(7), pp. 628–632.
Lim Soo-Yeon, Song Mu-Hee, Lee Sang-Jo (2004), The Construction of Domain Ontology and Its Application to Document Retrieval, [in:] T. Yakhno (ed.), Advances in Information Systems. ADVIS 2004, “Lecture Notes in Computer Science”, vol. 3261, Berlin–Heidelberg: Springer, pp. 117–127, https://doi.org/10.1007/978-3-540-30198-1_13
Munn Katherine, Smith Barry (2008), Applied Ontology: An Introduction, Frankfurt: Ontos Verlag.
Newman Mark, Barabási Albert-László, Watts J. Duncan (eds.) (2006), The Structure and Dynamics of Networks, New Jersey: Princeton University Press.
Quillian M. Ross (1968), Semantic memory, [in:] M. Minsky (ed.), Semantic information processing, Cambridge: MIT Press, pp. 216–270.
Ravenek Michael John, Rudman Debbie Laliberte (2013), Bridging Conceptions of Quality in Moments of Qualitative Research, “International Journal of Qualitative Methods”, vol. 12(1), pp. 436–456.
Sandelowski Margarete, Barroso Julie (2003), Classifying the Findings in Qualitative Studies, “Qualitative Health Research”, vol. 13(7), pp. 905–923.
Short Jeremy C., McKenny Aaron F., Reid Shane W. (2018), More Than Words? Computer-Aided Text Analysis in Organizational Behavior and Psychology Research, “Annual Review of Organizational Psychology and Organizational Behavior”, vol. 5(1), pp. 415–435, https://doi.org/10.1146/annurev-orgpsych-032117-104622
Taylor Chris, Coffey Amanda (2009), Editorial – Special Issue: Qualitative Research and Methodological Innovation, “Qualitative Research”, vol. 9(5), pp. 523–526.
Travers Max (2009), New Methods, Old Problems: A Sceptical View of Innovation in Qualitative Research, “Qualitative Research”, vol. 9(2), pp. 161–179.
Wang Dashun, Barabási Albert-László (2021), The Science of Science, Cambridge: University Press.
Wiedemann Gregor (2013), Opening up to Big Data: Computer-Assisted Analysis of Textual Data in Social Sciences, “Forum Qualitative Sozialforschung/Forum: Qualitative Social Research”, vol. 14(2), https://doi.org/10.17169/fqs-14.2.1949
Wiles Rose, Crow Graham, Pain Helen (2011), Innovation in Qualitative Research Methods: A Narrative Review, “Qualitative Research”, vol. 11(5), pp. 587–604.

